Posts tagged "emacs"
Text Editors
As far as I can tell, there has been a resurgence of development in the landscape of text editors of late. Only a few years ago, the text editing scene one the Mac seemed to be dominated by
- Crazy unix farts using Vim or Emacs
- BBEdit users
- Textmate users
During a very short period of time though, a raft of new text editors became available. Sublime Text in particular has been getting a lot of attention and rave reviews by many people. To me, this warrants another look at what these new (and old) text editors are offering.
Vim

Vim is very old software. It is a more or less direct descendant of ed from the early 1970s. It grew up in text based terminals without any graphical windows or mouses. Hence, all of its functionality is really meant to be used from the keyboard only, even though mousing is supported these days.
The terminal inheritance limits its graphical capabilities somewhat. There are no graphical drawers or animations or pixel-precise scrolling. Everything is displayed in terms of rectangular characters, hence scrolling can only ever scroll one line at a time and there are no graphical images anywhere. Since Vim predates graphical displays altogether, it does not adhere to its standards much. In fact, in its normal mode it won't even type out the characters you hit on your keyboard.
This is at really Vim's greatest strength and weakness: In its 'normal mode', all key presses are interpreted like keyboard shortcuts in other programs. And what shortcuts there are! Pretty much every key on the keyboard has some special function, most keys even serve multiple functions depending on what mode you are in at the moment. Thus it should come as no surprise that you can do anything with these shortcuts at astounding speed. Watching a seasoned Vimmer do his keyboard dance is something to behold. Moving the cursor is especially powerful. Usually, any place in the current file is reachable using just a few key strokes. But of course, you are not limited to just viewing one file at a time either: Vim supports arbitrary split views and can even be used for efficient diffing or merging. And when it comes to changing that text, Vim is no slouch, either. There are various registers for saving text or locations, there is an increadibly powerful macro system, amazing searching capabilities, command line integration, there are specialized functions for programming… Really, when it comes to pure text editing chops, nothing beats Vim.
Vim is also incredibly customizable. Of course, there is no graphical preferences windows to do the customization in. You customize Vim by editing simple text files. Vim even includes its very own scripting language, VimScript, to enable users to extend it. There is a huge wealth of plugins available. These range from file browsers to support for new languages, or even some limited integration with compilers or source control tools. However, VimScript is not exactly a very pleasant language to code in and Vim does not actually like to interface with external tools much. These two issues limit the scope of what is possible with Vim somewhat–deep compiler integration and graphical debugging are fiddly at best, so you will probably just keep a terminal open and do them there. That said, the plugin ecosystem for Vim is probably still leaps and bounds beyond what is possible with most other text editor out there, but it does not quite reach the same breadth or integration as some IDEs or Emacs do. All that power comes at a price. Learning Vim is hard. If you start out with Vim, it will probably take at least a week or so until you can approach your old productivity again. Mastering Vim will take years. Even after months and months of diligent learning, you will find some new tricks and features to increase your speed.
At the end of the day though, Vim is an amazingly powerful tool, and it is certainly worth it to at least learn the basics of it. Actually, most people I know who tried it have actually stuck with it. Myself, I have some two years of Vimming under my belt, too, and it has proven to be a very important tool for me.
Emacs 24

The thing you have to realize about Emacs is that… Emacs is powerful. People have called it the thermonuclear text editor, and for a reason. Emacs can edit text, of course, but that is really only the most mundane of its features. Really, Emacs is a little world of its own. You can read and write your mail from within Emacs, you can do spreadsheets, calendaring, it can host terminals, debuggers, compilers, there is Tetris, hell, it even includes its very own psychiatrist! Speaking off the record here, I have a suspicion that Emacs might achieve sentience pretty soon.
Similar to Vim, Emacs is old software. It was invented in the late 1970s at MIT and has been growing ever since. Also like Vim, its terminal inheritance shows its teeth sometimes: mouseweel scrolling can be awkward, especially if you like your inertial scrolling, the menu bar seems to not get much love and keyboard shortcuts are not conformant with what you might be used to from other text editors. On the other hand, Emacs has some very modern features like mixing of proportional fonts and fixed-width fonts or inline image display.
The upside of being old is that Emacs is very mature software. There is a ginormous selection of extensions available for Emacs, most of it actually distributed right with Emacs itself and a lot of it is superbly documented. Besides that, there are several integrated repositories for additional tools that can be downloaded and installed from the internet.
The real power of Emacs is in that it is really not so much a text editor but a virtual machine for a programming language called eLisp. Really anything that can possibly be written in Lisp and remotely involves text editing is possible and probably already available in Emacs. As such, Emacs probably has the most diverse feature set of any text editor out there. Most relevant to programmers will be debugger integration, automatic syntax and spell checking, powerful and context-aware autocompletion, refactoring capabilities and much much more. Emacs is the only program in this list which can actually be used as a full fledged IDE on its own.

But Emacs is not limited to programming at all. As mentioned before, it includes an Email client, a great calendar with an agenda, several IM clients, RSS readers, an astoundingly powerful outliner and spreadsheet editor, it is frequently used for blogging, writing screen plays, books or really anything you can think of.
The only real downside to this is that Emacs is, well, old. There is great power there, but is is only accessible to those willing to learn the myriad key combinations to invoke it. Rellay, mastering Emacs is a task for years, not weeks. But of course, you are not forced to wield all the power Emacs has to offer at once. Getting up to speed with basic text editing in Emacs will only take a few minutes, and the built-in help system and tutorial will guide you further whenever you feel the need to explore.
I have been using Emacs for several months now and I am really enjoying it. It has a few shortcomings, but it is constantly being improved and getting more modern every day. I can see myself giving in to it and just live in Emacs all day long, but for now, I'm happy with it just being my primary text editor. However, I can't quite get beyond the fact that its pure text editing chops are nowhere near Vim. Then again, Emacs does support Vim key bindings, so this might turn out not to bother me in the long run.
At any rate, I would recommend anyone to give Emacs a shot at least for a short while. The power of Emacs can be an exhilarating experience, really.
Textmate (2)

For the longest time, all GUI text editors could generally be classified as either Vim-based, Emacs-based or shortcut-based. The prevalent crop of shortcut-based GUI text editors mapped all its advanced functions to certain modifier-letter combinations and/or menu bar items.
When Textmate was introduced, it introduced a new concept: snippets. Snippets are short pieces of text which, upon activating a certain trigger, would expand to arbitraryly complex constructs.
Thus, to define a class in some programming language, you would type class, then hit TAB, and it would expand to a complete class declaration with constructor, destructor and documentation. Further yet, the class name would be highlighted immediately, so you could start editing it to your liking. These edits would even automatically percolate to all the relevant places in the class declaration and thus automatically change all scope declarations and the like.
Or, you could drag some image file into some LaTeX code and it would expand (dragging being the trigger here) to a whole \begin{figure} complete with \caption, \label, the correct path to the image and everything else you need.
This has proven to be such a popular feature that since Textmate's inception, implementations of snippets have been developed for pretty much every IDE or text editor out there.
Textmate also featured a very flexible and easily extensible regex based syntax parser, beautiful color schemes, a very elegant project management system and a vibrant community extending it in many directions. This was even more fascinating in that most of this functionality was implemented using a convenient shell scripting engine that could utilize any programming language your shell supported.
Sadly though, its main developer got stuck somewhere along the way and development all but dried up for five years. This primarily meant that some issues just would not be fixed and thus, got all the more jarring. Most prominently, Textmate lacked split views, regex incremental search and would only do single character undo/redos. Many people left Textmate because of this lack of progress.
While I was in college, I used Textmate extensively and it proved to be a veritable tool for many editing tasks. It is somewhat limited in its integration with programming tools, though, so don't expect any complex compiler or debugger integration. Ultimately, I left it behind for lack of cross platform compatibility and lack of development. There used to be a Windows program called E Text Editor, which wanted to become a fully compatible Textmate alternative for Windows and Linux, but development never even reached production quality.
Recently however, an early alpha version of Textmate 2 has been released that could reinvigorate the community and fix long standing issues. Whether that will actually happen will remain to be seen.
Vico

Vico is a very new application that has spung to live only in 2011 and is not finished yet. It aims to be a modern Vim, combining the virtue of the powerful mode-based editing system of Vim with a modern Cocoa interface. It even merges Vim's editing capabilities with Textmate-derived snippets and syntax highlighting.
Really, it tries to be an organic symbiosis of Vim and Textmate. And for most purposes, it very much succeeds in this. Syntax highlighting is very solid, there is a code browser, a nice file browser and full support for Textmate snippets. Vico even includes a powerful scripting environment that enables you to extend it in a language called Nu, which has the interesting aspect of being able to call into every object or method in the Cocoa libraries, thus opening the doors to a boundless world of wonders. Its Vim integration is well on its way, too. The most notable omission at this point are macros. The developer is working on it though and has promised to implement them in the near future. Some other areas are lacking, too, but if development continues I see no reason why it should not become a very nice text editor.
As it stands though, development of Vico is going slow and its community is not very large yet. Vico is a very nice tool, but at the end of the day, I miss the raw power of an actual Vim just as I miss the vibrant community around Textmate. If you are not spoiled by Vim yet or find Vim just a bit too ugly for your taste, you could give Vico a try though.
Personally, I like it quite a bit and I am hoping very much that it will not be forgotten as a failed attempt to modernize Vim. That said, what with Sublime Text 2 including a limited support for Vim key bindings, I can't really see Vico taking off.
Sublime Text 2

Sublime Text is a fairly recent development. It is a one-man project that has gained a lot of enthusiastic following in the last few months. In many ways, it feels like the next step in text editor development. Much like several other text editors out there, it has adopted Textmate snippets, color themes and syntax definitions as its core feature set. On top of that though, it has built a very powerful and flexible extension system that really sets it apart.
Do you remember CMD-T from Textmate? To open some file, you would hit CMD-T and start typing a file name. The name would be fuzzy matched to select from all available files. Thus, typing bcc would select BeaconController.cpp. This form of selection is increadibly intuitive and fast. It is also the basis for the extension system of Sublime Text. If there is no keyboard shortcut for a command, hit CMD-Shift-P and start typing to invoke the command.
In very much the same way as M-x in Emacs (though with fuzzy matching), this can invoke arbitrarily complex commands such as install bundle or using some refactoring library. Additionally, the same mechanism can be used to jump to method names or opening files. Really, these features are very efficient implementations of a code browser and file browser.
The second big thing about Sublime Text is just the ridiculous amount of polish it received. For example, if you have two files with the same name, it will prefix the tab titles with the folder they reside in. Simple, but so useful! If you jump around in a file, there is always a subtle scrolling animation. Even simple text selections have slightly rounded borders and just look amazingly beautiful.
Also of note is that Sublime Text supports multiple cursors. Want to change then name of all occurrences of a variable? Just select them all (!) and change them all at once. This is another amazingly useful feature. Its plugin system is based in Python, which is a refreshingly non-awkward choice for a text editor and spawned an astonishing amount of very interesting plugins already. Indeed the plugin system is flexible enough to support things like linters, source control integration and even something akin to Emacs's org-mode. And it also supports Vim key bindings. Not very complete, but easily enough to be useful. Oh, and it is available cross-platform on Mac, Windows and Linux, too.
I think there are three big families of text editors: Emacs, Vim, and shortcut-based text editors. Since I discovered Textmate however, I started believing that it represents a new branch in the big tree of text editors. Sublime Text seems to be the next step in the evolution of the Textmate branch.
Really, Sublime Text is an amazing achievement. Maybe not quite as hackable as Emacs and not quite as flexible as Vim, but easily beating both in terms of elegance and modernity. If you don't want to learn Emacs or Vim, Sublime Text is what you should use. In fact, it is the first text editor ever that has tempted me to leave Emacs and Vim behind. Nuff said.
What else is out there
Of course, that little list up there is by no means complete. Neither does it list all the amazing features these text editors have to offer, nor does it represent an exhaustive list of them. To the best of my knowledge, this is a short list of other text editors for the Mac platform. Note however, that I have never used any of them extensively and can only tell you stuff from heresay.
BBEdit

BBEdit is the big daddy of Mac text editors. It is currently available in version 10 and has a huge follwing predominantly amongst web developers. As far as I can tell, it includes amazing features for editing HTML. Maybe amongst the best out there. The remainder of its feature set seems rather standard crop though. There is some support for compilation, source code control, snippets, plugins… Though nothing on the level of Vim or Emacs really. Its most important disadvantage is probably its lack of cross-platform availability and extensibility.
TextWrangler

TextWrangler is the free smaller brother of BBEdit. Its feature set is somewhat pared down in comparison with BBEdit. In particular, it is missing BBEdit's famous HTML magic and some advanced external tool integration. Even for free, there are probably more capable candidates available, though maybe not at the same level of platform integration. That said, TextWrangler is not a bad choice and probably just fine for some casual text editing.
JEdit

I really don't know much about JEdit other than that it is written in Java, it has a sizeable following and it is available cross-platform. It seems like it could be about as useful as any shortcut based text editor can ever be, which is no small achievement. Also, it features a rich plugin system, of which I only heard good things. For all I know, this could be a very worthy alternative if you are on a budget (no Sublime Text) and don't want to learn Emacs or Vim.
Chocolat

Chocolat is yet another text editor that came into being in the post-Textmate void. It offers a good range of standard features, though notably missing advanced plugins apparently. Apart from that, it seems to be a solid shortcut based Mac text editor that is relatively cheap and actively developed.
Kod

Kod started out as an open source alternative to Textmate. This is quite uncommon for a post-Textmate text editor and worth supporting. After a good start however, the developer found a new job and development has pretty much stalled.
SubEthaEdit

The great thing about SubEthaEdit is collaborative editing. if you want to edit text collaboratively with several people, SubEthaEdit performs the task seamlessly and elegantly. Beyond that, it is a capable shortcut-based text editor. If you don't need the collaboration feature, you should probably look elsewhere though.
Smultron

Another venerable veteran on the Mac, Smultron used to be a free open source text editor that had a sizeable following. However, the developer ceased development at some point and later restarted the effort as a paid app in the Mac App Store. Smultron lost most of its following in that transition.
SlickEdit

SlickEdit is easily the most expensive text editor in this list. A single user license for one platform and one developer costs a scant 300 bucks. That is a lot of money for a text editor and is usually only shelled out only for business critical platform exclusive IDEs. It seems as if SlickEdit tries to be exactly that for general purpose text editing. It's feature list reads very well and checks all mayor boxes. It is available on pretty much any platform out there and is probably only rivalled by Emacs or Vim in that regard. It also supports emulation for Emacs or Vim key bindings. That said, 300-600 $ per developer is a pretty hefty price tag. Personally, I doubt that SlickEdit can live up to that price if you compare it to some of the other examples in this list. It is undoubtedly a well-maintained and powerful text editor though.
Komodo Edit

Komodo Edit is the free open source offspring of ActiveState's Komodo IDE. It's feature set is very complete and seems to be very worthy for many editing tasks. Being of IDE ancestry provides it with nice plugin support and very helpful deep language integration like sophisticated autocompletion and syntax checking. There are also quite good Vim key bindings and it is available on the three major platforms. However, its language support is limited to Perl, Python, Tcl, PHP, Ruby and Javascript. Probably not a bad choice if you can live with the language selection and are on a budget.
TextEdit

The built-in text editor in OSX. No syntax highlighting, project management or any programming support whatsoever make this a rather poor choice. There are plenty of free alternatives out there. That said, TextEdit does support rich text editing and might be of value for the odd letter to your grandma.
Text editors for web development
Strangely, all the major Mac text editors that cater specifically for web development are not cross platform. If web development is all you are ever doing though, these text editors might be well worth their money.
Coda

Combine the SubEthaEdit text editing engine including its collaborative tools with the great FTP program Transmit and you have CODA, the program for "one-window web development". It even includes a reference book to HTML in the package. For what it is, probably of great value and nice polish. As a general purpose text editor, there are better alternatives.
Espresso

Another text editor gearing specifically for web development. Thus, you get powerful HTML and CSS editing features and good support for typical web development languages such as PHP, Ruby or Markdoen, but no support for other languages. There is an extension system though that could improve language support. This might be a slightly less expensive alternative to Coda.
Taco HTML Editor

Another text editor geared exclusively towards web development. This time around though, there is no support for languages other than HTML, CSS and PHP, which makes this program a rather poor choice.
skEdit

skEdit supports a nice array of web development languages and offers a good range of features for a web development text editor. Also, it is pretty inexpensive in comparison to its brethren here. Probably a nice choice for web development if you are on a budget.
Text editing with confidence and Emacs
In college, I realized for the first time how a good text editor could save me serious time, when I dragged an image file into Textmate and it auto-inserted all the LaTeX boilerplate for a figure. A few years later, on my first job, I learned Vim key bindings for Visual Studio because I hated text editing in Visual Studio so much. This showed me another way how a good text editor could save me serious time. A year after that, I was bored and tried Emacs. With Emacs, I discovered the marvelous world of REPLs and outlining.
Note that this is not supposed to be a comparison between text editors. I have done that already. This will be a collection of some of the coolest things my text editor of choice is capable of. Stuff I love!
Text editing
In my admittedly short history of working with computers and text professionally I have realized a universal truth about the tools I like to use: A great tool is a tool I can trust. A tool I can use with confidence because I know that it will do what I want. Furthermore, a great tool is a tool that does what I want with a minimum amount of friction.
Here is one of my pet peeve with many text editors: Whenever I initiate a text search, a modal dialog box pops up where I have to enter the search phrase, then click a button to search for that word. In contrast great text editors allow searching for text without changing to a different window and show the results immediately while entering the search string. This is very fast and precise. In fact, it is so useful that searching is one of the most popular means of text navigation in text editors that have it.
This is a theme that goes through all these features: I look for stuff that is fast and precise, because this will enable more powerful applications of seemingly simple techniques.
Outlining and task management
Outlining is writing an hierarchical list of stuff that can be reordered and sub-trees can be hidden. I tried some graphical outliners before. I did not quite see the point of it. Instead, I always kept my todo lists in simple Markdown files. It worked well enough.
But with Emacs, I found out about org-mode, which is at its heart an outliner with a syntax somewhat like Markdown. It proved to be surprisingly powerful to be able to easily refile entries or whole sub-trees in my todo lists. Also, having trees be collapsible effectively enabled me to consolidate all my todo management into one file without that file becoming unmanageably big.
Add to that the more advanced task tracking features of org-mode, such as time tracking or advanced todo planning and this has become one of the most pivotal tools I use daily.
Shell interaction and operating system compatibility
Whenever my job required me to work on Windows, I often found it jarring to not have a command line available. Granted, there is Cygwin, but that does not play with the Windows directory structure too well. Also, many programs behave slightly differently on Linux, Cygwin and OSX. Basically, it drove me nuts.
Again, Emacs came to the rescue though: Eshell is a shell implemented in Emacs with no external dependencies. Thus, it comes installed on all my machines and works the same way on every operating system. Sadly though, Eshell is not quite full-featured and compatibility with some shell programs is kind of rough. In particular, it does not work well with less like scrolling buffers. However, some of those, like man or info are automatically opened in a special mode in Emacs itself, so this is not as bad as it sounds.
At more than one point, Eshell probably saved my sanity.
Git interaction
Source control is a crucial tool when working with source code. In college we used SVN. Even cooler is Git, though the initial learning curve is pretty bad. Personally, I learned it by mucking around on the command line and breaking stuff there, then using Tower to restore the repository to some sane state. Sadly though, Tower is OSX only, so I was kind of screwed on Windows and Linux.
Again, enter Emacs: Emacs has this magical mode called magit, which builds an interactive git interaction program within Emacs. With magit, all the major git commands are just a keystroke away and diffs or logs are easily accessible, too. It really is a major feat!
Grab bag
- Emacs' integrated ediff is a joy to use.
- REPLs are one honking great idea and come with most language modes for dynamic languages in Emacs.
- Emacs' LaTeX mode is amazingly powerful. Combine that with Emacs' ability to display PDF files graphically in a buffer and you have an awesome LaTeX environment.
- Emacs' documentation is wonderful. I learned many a trick just idly leafing through the built in Emacs documentation.
- Built in package management for extensions is a great time saver. This is available in Vim and Sublime Text as an addon, too.
- Lisp is indeed beautiful and elisp is quite joyful to program. I never really went beyond simple configuration in Vim. My
.emacsfile contains some quite sophisticated small programs though.
My Emacs customizations
I don't host my .emacs in a repository. I tried it for a while, but it did not work for me. I think repos are great for managing multiple divergent versions of the same source tree. However, my dotfiles should never diverge, they should just be kept in sync. This is what Dropbox is great at. So I use Dropbox instead of git.
One downside of that is that it is not as easy to provide a public link to my dotfiles. Or maybe it is. Here goes
Now on to the meat of this post: Some customizations I made that I think are cool.
When Emacs starts up, make it fit the left half of the screen
First, I need a function to set the size of a frame in terms of pixels. Emacs only provides set-frame-size, but that works on characters, not pixels.
(defun set-frame-pixel-size (frame width height)
"Sets size of FRAME to WIDTH by HEIGHT, measured in pixels."
(let ((pixels-per-char-width (/ (frame-pixel-width) (frame-width)))
(pixels-per-char-height (/ (frame-pixel-height) (frame-height))))
(set-frame-size frame
(floor (/ width pixels-per-char-width))
(floor (/ height pixels-per-char-height)))))
Next, a function that uses the above to set the frame size to exactly fit the left half of the screen. Note that the excess-... variables account for things like the menu bar, the dock or the task bar so you might have to adapt these values to your particular windowing environment. The values given here work for dockless OSX.
(defun use-left-half-screen ()
(interactive)
(let* ((excess-width 32)
(excess-height 48)
(half-screen-width (- (/ (x-display-pixel-width) 2) excess-width))
(screen-height (- (x-display-pixel-height) excess-height)))
(set-frame-pixel-size (selected-frame) half-screen-width screen-height)))
Finally, when Emacs starts up, make it use half the screen. Just how I like it!
(if window-system
(use-left-half-screen))
Make shell split windows auto-resize
Usually when you open a new split window in Emacs, it takes up half the frame. For some kinds of windows, I like them to be smaller. So here is a little snippet that shrinks some kinds of windows to 15 lines of height.
(add-hook 'window-configuration-change-hook
(lambda ()
(when (or (string-equal (buffer-name) "*Python*")
(string-equal (buffer-name) "*eshell*")
(string-equal (buffer-name) "*tex-shell*"))
(if (not (eq (window-height) 15))
(enlarge-window (- 15 (window-height)))))))
Create a new line above/below the current one
There is one feature of Vim that I really missed: o/O, which 'opens' a new line above or below the current one without changing the current line.
(defun vi-open-line-above ()
"Insert a newline above the current line and put point at beginning."
(interactive)
(unless (bolp)
(beginning-of-line))
(newline)
(forward-line -1)
(indent-according-to-mode))
(defun vi-open-line-below ()
"Insert a newline below the current line and put point at beginning."
(interactive)
(unless (eolp)
(end-of-line))
(newline-and-indent))
(global-set-key (kbd "C-o") 'vi-open-line-below)
(global-set-key (kbd "M-o") 'vi-open-line-above)
When editing LaTeX, show PDF output in Emacs
Emacs provides an awesome mode for editing LaTeX files. But isn't it sad that you always have to leave Emacs for viewing the PDF? Well, not any more.
This function will open or refresh a split window with the generated PDF file in it. Thus, when I edit LaTeX, I will hit C-c C-c to compile, then C-c C-v to see the PDF. All that without having to leave the LaTeX file.
;; open/show pdf file within Emacs using doc-view-mode
(defun open-show-pdf ()
(interactive)
(let ((tex-buffer-name (buffer-name))
(pdf-buffer-name (concat (TeX-master-file) ".pdf")))
(if (get-buffer pdf-buffer-name)
(switch-to-buffer-other-window pdf-buffer-name)
(find-file-other-window pdf-buffer-name))
(if (not (eq major-mode 'doc-view-mode))
(doc-view-mode))
(doc-view-revert-buffer t t)
(switch-to-buffer-other-window tex-buffer-name)))
(add-hook 'LaTeX-mode-hook
(lambda ()
(define-key LaTeX-mode-map (kbd "C-c C-v") 'open-show-pdf)
(visual-line-mode t)
(turn-on-reftex))
t)
Blogging with Emacs
When I first started blogging, it was on blogger.com (on the now-abandoned domain daskrachen.com). On blogger, writing new posts (back then) involved typing raw HTML into a web form. Not what I would call ideal. This improved somewhat when they introduced a fancy rich text editor that would automatically transform beautiful text into a horrible formatting mess.
Thus I switched. Getting my blog posts out of blogger was... Let's just say that I lost anything I didn't have a plain-text backup of. And I switched to Pelican, a static site generator written in Python. It worked beautifully, until I updated something, at which point it resorted to just throwing errors. Now I don't have anything in particular against Python stack traces, but these particular traces traced deep into stuff that was (then?) too complex for me to understand.
Thus I switched again. This time to C()λ∈slaw■, a static site generator written in Common Lisp. Mainly because I was interested in Common Lisp at the time. It worked really well. However, this was supposed to give me a chance to delve into Common Lisp, and I failed to understand C()λ∈slaw■'s code. Realistically though, this is probably not C()λ∈slaw■'s fault. My knowledge of Common Lisp is far from perfect.
Thus it was time to switch again. Having been enamored with Emacs for the last few years, it made sense to blog with Emacs as well. Besides, I am kind of fed up with the many conflicting flavors of Markdown out there and have switched my personal note-taking to Org mode long ago. So let's set up Emacs and Org as a blogging platform!
Before we start though, a short disclaimer: This will be a very bare bones blogging engine. It will consist of some articles, a front page, an archive page, and an RSS feed. And you will have to manage the front page and RSS feed semi-manually. No tags, no fancy history. Just what you see here.
On the plus side, this will be implemented entirely within Emacs and very simple to understand. Writing a new blog post will be as simple as writing an Org file and hitting a key combination! And you will get all of Org's fancy syntax highlighting and export magic for free!
Getting the pages to work is rather simple: You have to create a "publishing project" that specifies a base-directory where your Org files live and a publishing-directory, where the HTML files are going to be stored. Since this is Emacs, you could make your publishing directory any TRAMP path you like and insta-publish your workings!
(BTW, I am using Org 8.2.2 and I believe you need at least 8.0 for these examples to work)
(require 'ox-html)
(require 'ox-rss)
(require 'ox-publish)
(setq org-publish-project-alist
'(("blog-content"
:base-directory "~/Projects/blog/posts"
:html-extension "html"
:base-extension "org"
:publishing-directory "~/Projects/blog/publish"
:publishing-function (org-html-publish-to-html)
:recursive t ; descend into sub-folders?
:section-numbers nil ; don't create numbered sections
:with-toc nil ; don't create a table of contents
:with-latex t ; do use MathJax for awesome formulas!
:html-head-extra "" ; extra <head> entries go here
:html-preamble "" ; this stuff is put before your post
:html-postamble "" ; this stuff is put after your post
)))
Now hit M-x org-publish, type in blog-content, and you have a blog! Awesome! We are done here.
Well, how about an archive page that lists all your previous blog entries?
Emacs can auto-generate this for you. Simply add these lines to blog-content:
:auto-sitemap t
:sitemap-filename "archive.org"
:sitemap-title "Archive"
:sitemap-sort-files anti-chronologically
:sitemap-style list
:makeindex t
Also, you can put something like
<a href="archive.html">Other posts</a>
into your :html-postamble to make every page link to this. You can also add your Disqus snippet there to enable comments.
Adding a front page is simple, too. My front page is simply a normal page called index.org, which contains links and slugs for every article I want to have on the front page. For example:
#+TITLE: RECENT POSTS
* [[file:2013-05-30-speeding-up-matplotlib.org][Speeding up Matplotlib]]
#+include: "~/Projects/blog/posts/2013-05-30-speeding-up-matplotlib.org" :lines "4-9"
[[file:2013-05-30-speeding-up-matplotlib.org][read more...]]
But a blog is more than just text. There are images and CSS, too. I keep all that stuff in a separate directory and use a separate publishing project to copy it over to the publishing directory. Just add to your publishing-alist:
("blog-static"
:base-directory "~/Projects/blog/static"
:base-extension "png\\|jpg\\|css"
:publishing-directory "~/Projects/blog/publish/static"
:recursive t
:publishing-function org-publish-attachment)
Setting up the RSS feed works similarly. The RSS feed is created from a single Org file. Create a new publishing project and put it into your publishing-alist
("blog-rss"
:base-directory "~/Projects/blog/posts"
:base-extension "org"
:publishing-directory "~/Projects/blog/publish"
:publishing-function (org-rss-publish-to-rss)
:html-link-home "http://bastibe.de/"
:html-link-use-abs-url t
:exclude ".*"
:include ("rss.org")
:with-toc nil
:section-numbers nil
:title "Bastis Scratchpad on the Internet")
Make sure to exclude this rss.org from the blog-content project by adding it's name to the :exclude variable though. This rss.org file should contain headlines for every blog post. Every headline needs a publishing date and a permalink as property and the body of the post as content:
* Speeding up Matplotlib
:PROPERTIES:
:RSS_PERMALINK: "http://bastibe.de/2013-05-30-speeding-up-matplotlib.html"
:PUBDATE: <2013-05-30>
:END:
#+include: "~/Projects/blog/posts/2013-05-30-speeding-up-matplotlib.org" :lines "4-"
I exclude the first three lines, since they only contain #+title, #+date, and #+tags. You should at least exclude the #+title line. Otherwise, ox-rss will get confused about which title to choose for the feed.
You can even create a meta publishing project that executes all three projects in one fell swoop!
("blog"
:components ("blog-content" "blog-static" "blog-rss"))
There is one more thing that is kind of fiddly though: As I said, I use Disqus for comments, but I don't want to have comment boxes on the front page or the archive. Thankfully though, ox-html allows you to set :html-preamble and :html-postamble to a function, in which case that function can decide what pre/postamble to draw! The function can take an optional argument that contains a plist of article metadata. In this case, I decide on the :title metadata whether to print the archive link and Disqus, only the archive link, or neither:
:html-postamble
(lambda (info)
"Do not show disqus for Archive and Recent Posts"
(cond ((string= (car (plist-get info :title)) "Archive")
"")
((string= (car (plist-get info :title)) "Recent Posts")
"<div id=\"archive\"><a href=\"archive.html\">Other posts</a></div>")
(t
"<div id=\"archive\"><a href=\"archive.html\">Other posts</a></div>
<div id=\"disqus_thread\"></div>
<script type=\"text/javascript\">
..."
This should get you started! For completeness, here is my complete configuration:
(require 'ox-html)
(require 'ox-rss)
(require 'ox-publish)
(setq org-publish-project-alist
'(("blog"
:components ("blog-content" "blog-static" "blog-rss"))
("blog-content"
:base-directory "~/Projects/blog/posts"
:html-extension "html"
:base-extension "org"
:publishing-directory "~/Projects/blog/publish"
:publishing-function (org-html-publish-to-html)
:auto-sitemap t
:sitemap-filename "archive.org"
:sitemap-title "Archive"
:sitemap-sort-files anti-chronologically
:sitemap-style list
:makeindex t
:recursive t
:section-numbers nil
:with-toc nil
:with-latex t
:html-head-include-default-style nil
:html-head-include-scripts nil
:html-head-extra
"<link rel=\"alternate\" type=\"appliation/rss+xml\"
href=\"http://bastibe.de/rss.xml\"
title=\"RSS feed for bastibe.de\">
<link href='http://fonts.googleapis.com/css?family=Roboto&subset=latin' rel='stylesheet' type='text/css'>
<link href='http://fonts.googleapis.com/css?family=Ubuntu+Mono' rel='stylesheet' type='text/css'>
<link href= \"static/style.css\" rel=\"stylesheet\" type=\"text/css\" />
<title>Basti's Scratchpad on the Internet</title>
<meta http-equiv=\"content-type\" content=\"application/xhtml+xml; charset=UTF-8\" />
<meta name=\"viewport\" content=\"initial-scale=1,width=device-width,minimum-scale=1\">"
:html-preamble
"<div class=\"header\">
<a href=\"http://bastibe.de\">Basti's Scratchpad on the Internet</a>
<div class=\"sitelinks\">
<a href=\"http://alpha.app.net/bastibe\">alpha.app.net</a> | <a href=\"http://github.com/bastibe\">Github</a>
</div>
</div>"
:html-postamble
(lambda (info)
"Do not show disqus for Archive and Recent Posts"
(cond ((string= (car (plist-get info :title)) "Archive") "")
((string= (car (plist-get info :title)) "Recent Posts")
"<div id=\"archive\"><a href=\"archive.html\">Other posts</a></div>")
(t
"<div id=\"archive\"><a href=\"archive.html\">Other posts</a></div>
<div id=\"disqus_thread\"></div>
<script type=\"text/javascript\">
/* * * CONFIGURATION VARIABLES: EDIT BEFORE PASTING INTO YOUR WEBPAGE * * */
var disqus_shortname = 'bastibe';
/* * * DON'T EDIT BELOW THIS LINE * * */
(function() {
var dsq = document.createElement('script');
dsq.type = 'text/javascript';
dsq.async = true;
dsq.src = 'http://' + disqus_shortname + '.disqus.com/embed.js';
(document.getElementsByTagName('head')[0] || document.getElementsByTagName('body')[0]).appendChild(dsq);
})();
</script>
<noscript>Please enable JavaScript to view the
<a href=\"http://disqus.com/?ref_noscript\">comments powered by Disqus.</a></noscript>
<a href=\"http://disqus.com\" class=\"dsq-brlink\">comments powered by <span class=\"logo-disqus\">Disqus</span></a>")))
:exclude "rss.org\\|archive.org\\|theindex.org")
("blog-rss"
:base-directory "~/Projects/blog/posts"
:base-extension "org"
:publishing-directory "~/Projects/blog/publish"
:publishing-function (org-rss-publish-to-rss)
:html-link-home "http://bastibe.de/"
:html-link-use-abs-url t
:exclude ".*"
:include ("rss.org")
:with-toc nil
:section-numbers nil
:title "Bastis Scratchpad on the Internet")
("blog-static"
:base-directory "~/Projects/blog/static"
:base-extension "png\\|jpg\\|css"
:publishing-directory "~/Projects/blog/publish/static"
:recursive t
:publishing-function org-publish-attachment)))
All other sources, including the source code to all blog posts, can be found on Github (the master branch contains HTML, the source branch contains Org).
Addendum: I have since discovered that org-rss-publish-to-rss only handles top-level headlines, but disregards second-level or higher-level headlines. Thus, if you have a post with nested headlines, your RSS feed will only include the text of the top-level one. To fix this, I advised org-rss-publish-to-rss to use org-html-headline for non-top-level headlines like this:
(defadvice org-rss-headline
(around my-rss-headline (headline contents info) activate)
"only use org-rss-headline for top level headlines"
(if (< (org-export-get-relative-level headline info) 2)
ad-do-it
(setq ad-return-value (org-html-headline headline contents info))))
Now, the RSS feed includes the full text of all articles.
Speeding Up Org Mode Publishing
I use org-mode to write my blog, and org-publish as my static site generator. While this system works great, I have found it to be really really slow. At this point, my blog has 39 posts, and org-publish will take upwards of a minute to re-generate all of them. To make matters worse, my workflow usually involves several re-generations per post. This gets old pretty quickly.
Since I am on a long train ride today, I decided to have a go at this problem. By the way, train rides and hacking on Emacs are a perfect match: Internet connectivity on trains is usually terrible, but Emacs is self-documenting, so internet access doesn't matter as much. It is sobering to work without an internet connection every once in a while, and Emacs is a perfect target for this kind of work.
One of the many things I learned on train rides is that Emacs in fact contains its own profiler! So, I ran (progn (profiler-start 'cpu) (org-publish "blog") (profiler-report)) to get a hierarchical list of where org-publish was spending its time. Turns out, most of its total run time was spent in functions relating to version control (starting with vc-).
Some package in my configuration set up vc-find-file-hook as part of find-file-hook. This means that every time org-publish opens a file, Emacs will look for the containing git repository and query its status. This takes forever! Worse yet, I don't even use vc-git at all. All my git interaction is done through magit.
But Emacs wouldn't be Emacs if this could not be fixed with a line or two of elisp. (remove-hook 'find-file-hooks 'vc-find-file-hook) will do the trick. This brought the runtime of org-publish down to 15 seconds. Yay for profiling and yay for Emacs!
Org Mode Citation Links
I am writing my master's thesis in Org Mode, and export to LaTeX for publishing. For the most part, this works incredibly well. Using Org Mode instead of plain LaTeX means no more fiddly \backslash{curly brace} all over the place. No more scattering code fragments and markup across hundreds of files. And on top of that, deep integration with my research notes and task tracking system.
But not everything is perfect. For one thing, citations do not work well. Sure, you can always write \cite{cohen93}, but then you are writing LaTeX again. Also, all the other references and footnotes are clickable, highlighted Org Mode links, but \cite{cohen93} is just inline LaTeX.
But luckily, this is Emacs, and Emacs is programmable. And better yet, Org Mode has just the tool for the job:
(org-add-link-type "cite"
(defun follow-cite (name)
"Open bibliography and jump to appropriate entry.
The document must contain \bibliography{filename} somewhere
for this to work"
(find-file-other-window
(save-excursion
(beginning-of-buffer)
(save-match-data
(re-search-forward "\\\\bibliography{\\([^}]+\\)}")
(concat (match-string 1) ".bib"))))
(beginning-of-buffer)
(search-forward name))
(defun export-cite (path desc format)
"Export [[cite:cohen93]] as \cite{cohen93} in LaTeX."
(if (eq format 'latex)
(if (or (not desc) (equal 0 (search "cite:" desc)))
(format "\\cite{%s}" path)
(format "\\cite[%s]{%s}" desc path)))))
This registers a new link type in Org Mode: , which will jump to the appropriate bibliography entry when clicked, and get exported as \cite{cohen93} in LaTeX. Awesome!
Writing a Thesis in Org Mode
Most of my peers write all their scientific documents in LaTeX. Being a true believer in the power of Emacs, I opted for writing my master's thesis in Org Mode instead. Here's my thoughts on this process and how it compares to the usual LaTeX work flow.
In my area of study, a thesis is a document of about 60 pages that contains numerous figures, math, citations, and the occasional table or source code snippet. Figures are usually graphs that are generated in some programming environment and creating those graphis is a substantial part of writing the thesis.
Org mode was a huge help in this regard, since it combines the document text and the executable pieces of code. Instead of having a bunch of scripts that generate graphs, and a bunch of LaTeX files that include those graphs, I had one big Org file that included both the thesis text and the graphing code.
As for the thesis text, I used Org's export functionality to convert the Org source to LaTeX, and compiled a PDF from there. This really works very well: It is very nice to use Org headlines instead of \section{...}, and clickable Org links instead of \ref{...}. While this is nice, it is just a change of syntax. I still had to enter the very same things and saving a few characters is not particularly impressive. For example, figures still require a caption, an ID, and a size:
#+CAPTION: Modulation tracks of a clarinet recording with and without white noise. The modulation tracks are not normalized.
#+ATTR_LATEX: :width 6in :height 2.5in :float multicolumn
#+NAME: fig:summary_tracks
[[file:images/summary_tracks.pdf]]
In LaTeX, this would be
\begin{figure*}
\centering
\includegraphics[width=6in,height=2.5in]{images/summary_tracks.pdf}
\caption{\label{fig:summary_tracks}Modulation tracks of a clarinet recording with and without white noise. The modulation tracks are not normalized.}
\end{figure*}
As you can see, there really is not that much of a difference between these two, and you might even consider the LaTeX example more readable. In some other areas, Org mode is simply lacking features: Org does not have any syntax for page formatting, and thus can't create a perfectly formatted title page. Similarly, it can't do un-numbered sections, and it can't do numbered equations. For all of those, I had to fall back to writing LaTeX. This is not a big deal, but it breaks the abstraction.
A bigger problem is that Org documents include all the chapters in one big file. While Org can deal with large files no problem, it means that LaTeX compiles take a while. In LaTeX, I would have split my document into a number of smaller files that could be separately compiled in order to keep compilation time down. This is confounded by Org's default behavior of deleting intermediate LaTeX files, which forces a full triple-recompile on each export. At the end of my thesis, a full export took about 15 seconds. Not a deal-breaker, but annoying.
The one thing where Org really shines, though, is the inclusion of code fragments: Most of my figures were created in Python, and Org mode allowed me to include that Python code right in my document. Hit C-c C-c on any code fragment, and Org ran that code and created a new image file that is automatically included as a figure. This was really tremendously useful!
At the end of the day, I am not sure whether Org mode is the right tool for writing a thesis. It worked fine, but there were a lot of edge cases and workarounds, which made the whole process a bit uncomfortable. The only really strong argument in favor of Org is the way it can include both code and prose in the same document. But maybe a similar thing could be implemented with LaTeX and some literate programming tool.
Org Mode Selective Section Numbering
This is the third revision of a post about selective headline numbering in Org mode. On its own, Org mode can either number all headlines, or none. For scientific writing, this is a non-starter. In a scientific paper, the abstract should not be numbered, the main body should be numbered, and appendices should not be numbered.
In LaTeX, this is easy to do: \section{} creates a numbered headline, while \section*{} creates an unnumbered section. Org mode does not have any facility to control this on a per-headline basis, but it can be taught:
(defun headline-numbering-filter (data backend info)
"No numbering in headlines that have a property :numbers: no"
(let* ((beg (next-property-change 0 data))
(headline (if beg (get-text-property beg :parent data))))
(if (and (eq backend 'latex)
(string= (org-element-property :NUMBERS headline) "no"))
(replace-regexp-in-string
"\\(part\\|chapter\\|\\(?:sub\\)*section\\|\\(?:sub\\)?paragraph\\)"
"\\1*" data nil nil 1)
data)))
(setq org-export-filter-headline-functions '(headline-numbering-filter))
This creates a filter (an Org mode convention similar to a hook), which appends the asterisk to LaTeX headlines if the headline has a property :NUMBERS: no. If all you do is export to LaTeX, this works well.
If you need to export to HTML as well, things get more complicated. Since HTML does not have native numbering support, Org is forced to manually create section numbers. But times have changed, and with CSS3, HTML now indeed does support native numbering!
Here is some CSS that uses CSS3 counters to number all headlines and hide Org's numbers:
/* hide Org-mode's section numbers */
span.section-number-2 { display: none; }
span.section-number-3 { display: none; }
span.section-number-4 { display: none; }
span.section-number-5 { display: none; }
span.section-number-6 { display: none; }
/* define counters for the different headline levels */
h1 { counter-reset: section; }
h2 { counter-reset: subsection; }
h3 { counter-reset: subsubsection; }
h4 { counter-reset: paragraph; }
h5 { counter-reset: subparagraph; }
/* prepend section numbers before headlines */
h2::before {
content: counter(section) " ";
counter-increment: section;
}
h3::before {
content: counter(section) "." counter(subsection) " ";
counter-increment: subsection;
}
h4::before {
content: counter(section) "." counter(subsection) "." counter(subsubsection) " ";
counter-increment: subsubsection;
}
h5::before {
content: counter(section) "." counter(subsection) "." counter(subsubsection) "." counter(paragraph) " ";
counter-increment: paragraph;
}
h6::before {
content: counter(section) "." counter(subsection) "." counter(subsubsection) "." counter(paragraph) "." counter(subparagraph) " ";
counter-increment: subparagraph;
}
/* suppress numbering for headlines with class="nonumber" */
.nonumber::before { content: none; }
With this in place, we can extend the previous filter to work for HTML as well as LaTeX:
(defun headline-numbering-filter (data backend info)
"No numbering in headlines that have a property :numbers: no"
(let* ((beg (next-property-change 0 data))
(headline (if beg (get-text-property beg :parent data))))
(if (string= (org-element-property :NUMBERS headline) "no")
(cond ((eq backend 'latex)
(replace-regexp-in-string
"\\(part\\|chapter\\|\\(?:sub\\)*section\\|\\(?:sub\\)?paragraph\\)"
"\\1*" data nil nil 1))
((eq backend 'html)
(replace-regexp-in-string
"\\(<h[1-6]\\)\\([^>]*>\\)"
"\\1 class=\"nonumber\"\\2" data nil nil)))
data)))
(setq org-export-filter-headline-functions '(headline-numbering-filter))
Previously, I implemented this in Org mode only (no CSS). While that worked as well, it required the modification of some fairly low-level Org functions. The CSS-based solution is much simpler, and should be much easier to maintain and adapt.
Multi-Font Themes in Emacs
Traditionally, text editor themes are all about colors, right? In programming, we use color to tell variables from type declarations, comments, or strings. However, any other text document uses typography instead of color to distinguish between headlines, list items, and keywords. I think that our current approach to highlighting code is misguided.
I think that color themes are an accident of history. Terminal text editors are unable to switch fonts. All they can do is switch colors, so colors is all we use. But in todays graphical world, we are no longer bound by the shackles of terminals, and Emacs can switch fonts just as easily as colors1.
It all started about a year ago, when I fell in love with a font called PragmataPro. One of the coolest features of Pragmata was its native bold and italic letters, and its wide support for unicode symbols. I had to find a use for these features! And so, down the rabbit hole I went. Keywords should be bold! # Comments should be italic! And while we're at it, why not add some underlines? And so on.
The logical next step was then to get rid of colors altogether. At first, as an experiment. Do I really need colors in code? The very pretty eink theme seemed to claim otherwise. After a few months of this lunacy, I realized that while I didn't strictly need colors, the stylistic variations of just one font aren't quite sufficient for source code. In particular, it wasn't always easy to distinguish between italic and roman type in PragmataPro, which lead to some confusion.
But then, inspiration hit me: Who says that I could only use one single font? No one!
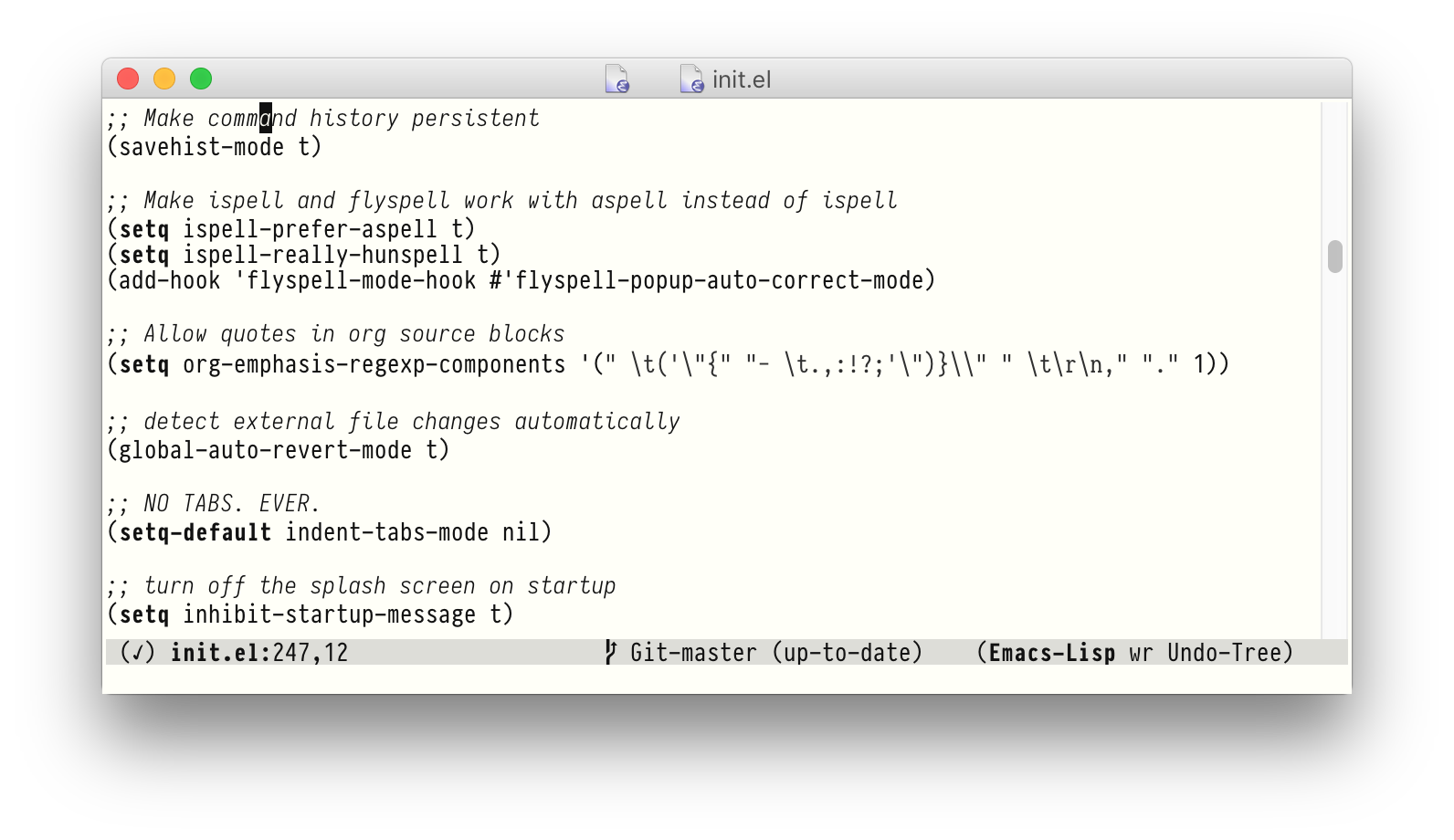
The tricky bit is to find fonts that work well together. In this example, I'm using PragmataPro for all regular code, Iosevka Slab2 for strings, and oblique3 Iosevka for comments. Ubuntu Mono and InputCompressed work well, too. You can find my current theme on Github. The only downside is that while these fonts share the character width, the heights differ slightly, which sometimes leads to uneven line heights.
Still, I love the look of this! (Of course it won't work in a terminal, or most other text editors.)
Installing Emacs on Windows
The official website states that you need to download Emacs from a nearby GNU mirror. However, this does not install gnutls, which is required for installing packages from melpa or marmalade. The documentation says that this can be obtained from ezwinports.
However, I have found that this does not work any more: As of Emacs 25, Emacs is available in 64 bit, but ezwinport only supplies 32 bit binaries. I had to search a bit, but the (in retrospect, obvious) solution is to download the required binaries from GnuTLS's website, directly. Then unpack all *.dll from the bin directory to your Emacs's bin directory, and you are good to go.
This situation is really a bit sad. Installing Emacs should not be this hard. But there is talk about providing a Windows installer for Emacs in one of the next versions, which will hopefully fix these issues.
Speeding up org-static-blog
Three years ago, I had enough of all the static site generators out there. Over the life of this blog, I had used Octopress, then Pelican, then Coleslaw, then org-mode, and then wrote my own static site generator, org-static-blog. Above all, org-static-blog is simple. It iterates over all *.org files in org-static-blog-posts-directory, and then exports all of these files to HTML. Simple is good. Simple is reliable. Simple means I can fix things.
However, simple can also mean inefficient. Most glaringly, org-static-blog exports every single blog post three times every time you publish: Once to render the HTML, then once to render the RSS feed, then once to render the Index and Archive pages.
Today, I finally tackled this problem: Now, org-static-blog only exports each post once, when the *.org file changes. The RSS feed, the Index page, and the Archive page simply read the already-rendered HTML instead of exporting again.
Thus, a full rebuild of this blog and all of its 85 posts used to take 2:12 min, and now takes 42 s. More importantly, if only one org file changed, the rebuild used to take 1:08 min, and now takes 1.5 s. Things like this are hugely satisfying to me!
How to Write a Dissertation
Assembling scientific documents is a complex task. My documents are a combination of graphs, data, and text, written in LaTeX. This post is about combining these elements, keeping them up to date, while not losing your mind. My techniques work on any Unix system on Linux, macOS, or the WSL.
Text
For engineering or science work, my deliverables are PDFs, typically rendered from LaTeX. But writing LaTeX is not the most pleasant of writing environments. So I've tried my hand at org-mode and Markdown, compiled them to LaTeX, and then to PDF. In general, this worked well, but there always came a point where the abstraction broke, and the LaTeX leaked up the stack into my document. At which point I'd essentially write LaTeX anyway, just with a different syntax. After a few years of this, I decided to cut the middle-man, bite the bullet, and just write LaTeX.
That said, modern LaTeX is not so bad any more: XeLaTeX supports normal OpenType fonts, mixed languages, proper unicode, and natively renders to PDF. It also renders pretty quickly. My entire dissertation renders in less than three seconds, which is plenty fast enough for me.
To render, I run a simple makefile in an infinite loop that recompiles my PDF whenever the TeX source changes, giving live feedback while writing:
diss.pdf: diss.tex makefile $(graph_pdfs)
xelatex -interaction nonstopmode diss.tex
We'll get back to graph_pdfs in a second.
Graphs
A major challenge in writing a technical document is keeping all the source data in sync with the document. To make sure that all graphs are up to date, I plug them into the same makefile as above, but with a twist: All my graphs are created from Python scripts of the same name in the graphs directory.
But you don't want to simply execute all the scripts in graphs, as some of them might be shared dependencies that do not produce PDFs. So instead, I only execute scripts that start with a chapter number, which conveniently sorts them by chapter in the file manager, as well.
Thus all graphs render into the main PDF and update automatically, just like the main document:
graph_sources = $(shell find graphs -regex "graphs/[0-9]-.*\.py")
graph_pdfs = $(patsubst %.py,%.pdf,$(graph_sources))
graphs/%.pdf: graphs/%.py
cd graphs; .venv/bin/python $(notdir $<)
The first two lines build a list of all graph scripts in the graphs directory, and their matching PDFs. The last two lines are a makefile recipy that compiles any graph script into a PDF, using the virtualenv in graphs/.venv/. How elegant these makefiles are, with recipe definitions independent of targets.
This system is surprisingly flexible, and absolutely trivial to debug. For example, I sometimes use those graph scripts as glorified shell scripts, for converting an SVG to PDF with Inkscape or some similar task. Or I compile some intermediate data before actually building the graph, and cache them for later use. Just make sure to set an appropriate exit code in the graph script, to signal to the makefile whether the graph was successfully created. An additional makefile target graphs: $(graph_pdfs) can also come in handy if you want ignore the TeX side of things for a bit.
Data
All of the graph scripts and TeX are of course backed by a Git repository. But my dissertation also contains a number of databases that are far too big for Git. Instead, I rely on git-annex to synchronize data across machines from a simple webdav host.
To set up a new writing environment from scratch, all I need is the following series of commands:
git clone git://mygitserver/dissertation.git dissertation
cd dissertation
git annex init
env WEBDAV_USERNAME=xxx WEBDAV_PASSWORD=yyy git annex enableremote mywebdavserver
git annex copy --from mywebdavserver
(cd graphs; pipenv install)
make all
This will download my graphs and text from mygitserver, download my databases from mywebdavserver, build my Python environment with pipenv, recreate all the graph PDFs, and compile the TeX. A process that can take a few hours, but is completely automated and reliable.
And that is truly the key part; The last thing you want to do while writing is being distracted by technical issues such as "where did I put that database again?", "didn't that graph show something different the other day?", or "I forgot to my database file at work and now I'm stuck at home during the pandemic and can't progress". Not that any of those would have ever happened to me, of course.
🪦 Emacs 2011-2023
For the last dozen years, I have used Emacs as my text editor and development environment. But this era ended. In this post, I outline how I went from using Emacs as a cornerstone of my digital life, to abandoning it.
In an ironic twist of history, it was Visual Studio that drove me to Emacs in the first place, and what ultimately pulled me away from it: In 2011, I was working on the firmware of a digital mixing console. This was edited in Visual Studio, compiled with an embedded compiler software, and source-controlled with command-line Git. It was ultimately Emacs that allowed me to tie this hodgepodge of idiosyncratic C+1, Git, and the proprietary compiler into a somewhat sane development environment.
Over the years, my Emacs config grew, I learned Elisp, I published my own Emacs packages, and developed my own Emacs theme. I went back to university, did my PhD, worked both OSS and commercially, and almost all of this was done in Emacs. As particular standouts beyond traditional text editing, I used Emacs' Git-client Magit every single day, and my own org-journal was absolutely vital as my research/work journal.

In 2023, however, I started a new job, once again with a Visual Studio codebase. This time, however, the code base and build system was tightly woven into the Visual Studio IDE, and only really navigable and editable therein. It thus made no sense to edit this code in Emacs, so I didn't. Perhaps I also needed a break.
And as my Emacs usage waned, so its ancient keyboard shortcuts started to become a liability. I started mis-typing Emacs things in Visual Studio, and hitting Windows shortcuts in Emacs. Friction began to arise. At the same time, I started noticing how poorly Emacs runs on Windows. Startup takes many seconds, it does not integrate well into the task bar2, it doesn't handle resolution changes gracefully, and it's best I don't start talking about its horrendously broken mouse scrolling. And of course it can't scroll point out of the window3.
My last use-case for Emacs was org-journal. I ended up porting a basic version of it to Visual Studio Code. Having thus written a text editor plugin for both editors, I have to be blunt: both, the anachronistic bone-headedness of Elisp, and the utter insanity of TypeScript's node APIs, are terrible environments for writing plugins. A few years ago I did the same exercise in Sublime Text Python, which was a beautiful, simple, quick affair. But I do enjoy a programming puzzle, so here we are.
The final nail in Emacs' coffin came from an unexpected corner: For all my professional life, I was a solo coder. My Emacs was proudly black-and-white (different fonts instead of different colors!), and my keyboard shortcuts were idiosyncratically my own. I did not merely use Emacs. I had built MY OWN Emacs. I like to think this built character, and API design experience. But it was of course a complete non-starter for pair programming. After having tasted Visual Studio (± Code) Live Sharing, there was simply no going back.
And thus, I am saddened to see that I haven't started Emacs in several weeks. I guess this is goodbye. This blog is still rendered by Emacs, and I still maintain various Emacs modules. My journal is still written in org-mode. But it is now edited in Visual Studio Code.
An eclectic subset of C+
, intersected with the limitations of the embedded compiler. This was decidedly pre-"modern" C+, and probably less than the sum of its parts.↩Usually, the program's taskbar button starts the program, and represents it while running. Emacs spawns a new button instead.↩
This is emacs-speak for "it can't scroll the cursor outside the viewport"↩
