Posts tagged "audio"
Real Time Signal Processing in Python
Wouldn't it be nice if you could do real time audio processing in a convenient programming language? Matlab comes to mind as a convenient language for signal processing. But while Matlab is pretty fast, it is really only fast for algorithms that can be vectorized. In audio however, we have many algorithms that need knowledge about the previous sample to calculate the next one, so they can't be vectorized.
But this is not going to be about Matlab. This is going to be about Python. Combine Python with Numpy (and Scipy and Matplotlib) and you have a signal processing system very comparable to Matlab. Additionally, you can do real-time audio input/output using PyAudio. PyAudio is a wrapper around PortAudio and provides cross platform audio recording/playback in a nice, pythonic way. (Real time capabilities were added in 0.2.6 with the help of yours truly).
However, this does not solve the problem with vectorization. Just like Matlab, Python/Numpy is only fast for vectorizable algorithms. So as an example, let's define an iterative algorithm that is not vectorizable:
A Simple Limiter
A limiter is an audio effect that controls the system gain so that it does not exceed a certain threshold level. One could do this by simply cutting off any signal peaks above that level, but that sounds awful. So instead, the whole system gain is reduced smoothly if the signal gets too loud and is amplified back to its original gain again when it does not exceed the threshold any more. The important part is that the gain change is done smoothly, since otherwise it would introduce a lot of distortion.
If a signal peak is detected, the limiter will thus need a certain amount of time to reduce the gain accordingly. If you still want to prevent all peaks, the limiter will have to know of the peaks in advance, which is of course impossible in a real time system. Instead, the signal is delayed by a short time to give the limiter time to adjust the system gain before the peak is actually played. To keep this delay as short as possible, this "attack" phase where the gain is decreased should be very short, too. "Releasing" the gain back up to its original value can be done more slowly, thus introducing less distortion.
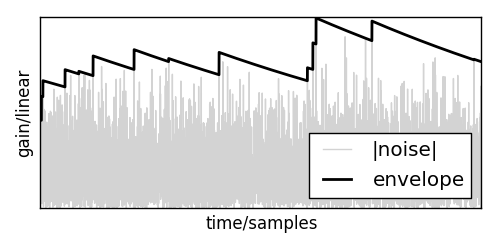
With that out of the way, let me present you a simple implementation of such a limiter. First, lets define a signal envelope \(e[n]\) that catches all the peaks and smoothly decays after them:
where \(s[n]\) is the current signal and \(0 < f_r < 1\) is a release factor.
If this is applied to a signal, it will create an envelope like this:
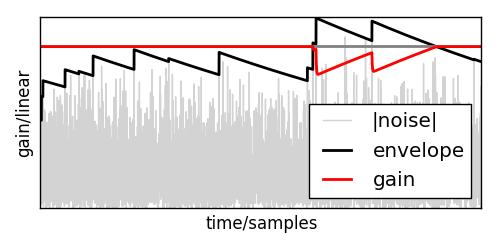
Based on that envelope, and assuming that the signal ranges from -1 to 1, the target gain \(g_t[n]\) can be calculated using
Now, the output gain \(g[n]\) can smoothly move towards that target gain using
where \(0 < f_a \ll f_r\) is the attack factor.
Here you can see how that would look in practice:
Zooming in on one of the limited section reveals that the gain is actually moving smoothly.
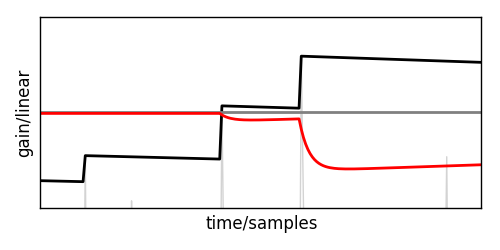
This gain can now be multiplied on the delayed input signal and will safely keep that below the threshold.
In Python, this might look like this:
class Limiter:
def __init__(self, attack_coeff, release_coeff, delay, dtype=float32):
self.delay_index = 0
self.envelope = 0
self.gain = 1
self.delay = delay
self.delay_line = zeros(delay, dtype=dtype)
self.release_coeff = release_coeff
self.attack_coeff = attack_coeff
def limit(self, signal, threshold):
for i in arange(len(signal)):
self.delay_line[self.delay_index] = signal[i]
self.delay_index = (self.delay_index + 1) % self.delay
# calculate an envelope of the signal
self.envelope *= self.release_coeff
self.envelope = max(abs(signal[i]), self.envelope)
# have self.gain go towards a desired limiter gain
if self.envelope > threshold:
target_gain = (1+threshold-self.envelope)
else:
target_gain = 1.0
self.gain = ( self.gain*self.attack_coeff +
target_gain*(1-self.attack_coeff) )
# limit the delayed signal
signal[i] = self.delay_line[self.delay_index] * self.gain
Note that this limiter does not actually clip all peaks completely, since the envelope for a single peak will have decayed a bit before the target gain will have reached it. Thus, the output gain will actually be slightly higher than what would be necessary to limit the output to the threshold. Since the attack factor is supposed to be significantly smaller than the release factor, this does not matter much though.
Also, it would probably be more useful to define the factors \(f_a\) and \(f_r\) in terms of the time they take to reach their target and the threshold \(t\) in dB FS.
Implementing audio processing in Python
A real-time audio processing framework using PyAudio would look like this:
(callback is a function that will be defined shortly)
from pyaudio import PyAudio, paFloat32
pa = PyAudio()
stream = pa.open(format = paFloat32,
channels = 1,
rate = 44100,
output = True,
frames_per_buffer = 1024,
stream_callback = callback)
while stream.is_active():
sleep(0.1)
stream.close()
pa.terminate()
This will open a stream, which is a PyAudio construct that manages input and output to/from one sound device. In this case, it is configured to use float values, only open one channel, play audio at a sample rate of 44100 Hz, have that one channel be output only and call the function callback every 1024 samples.
Since the callback will be executed on a different thread, control flow will continue immediately after pa.open(). In order to analyze the resulting signal, the while stream.is_active() loop waits until the signal has been processed completely.
Every time the callback is called, it will have to return 1024 samples of audio data. Using the class Limiter above, a sample counter counter and an audio signal signal, this can be implemented like this:
limiter = Limiter(attack_coeff, release_coeff, delay, dtype)
def callback(in_data, frame_count, time_info, flag):
if flag:
print("Playback Error: %i" % flag)
played_frames = counter
counter += frame_count
limiter.limit(signal[played_frames:counter], threshold)
return signal[played_frames:counter], paContinue
The paContinue at the end is a flag signifying that the audio processing is not done yet and the callback wants to be called again. Returning paComplete or an insufficient number of samples instead would stop audio processing after the current block and thus invalidate stream.is_active() and resume control flow in the snippet above.
Now this will run the limiter and play back the result. Sadly however, Python is just a bit too slow to make this work reliably. Even with a long block size of 1024 samples, this will result in occasional hickups and discontinuities. (Which the callback will display in the print(...) statement).
Speeding up execution using Cython
The limiter defined above could be rewritten in C like this:
// this corresponds to the Python Limiter class.
typedef struct limiter_state_t {
int delay_index;
int delay_length;
float envelope;
float current_gain;
float attack_coeff;
float release_coeff;
} limiter_state;
#define MAX(x,y) ((x)>(y)?(x):(y))
// this corresponds to the Python __init__ function.
limiter_state init_limiter(float attack_coeff, float release_coeff, int delay_len) {
limiter_state state;
state.attack_coeff = attack_coeff;
state.release_coeff = release_coeff;
state.delay_index = 0;
state.envelope = 0;
state.current_gain = 1;
state.delay_length = delay_len;
return state;
}
void limit(float *signal, int block_length, float threshold,
float *delay_line, limiter_state *state) {
for(int i=0; i<block_length; i++) {
delay_line[state->delay_index] = signal[i];
state->delay_index = (state->delay_index + 1) % state->delay_length;
// calculate an envelope of the signal
state->envelope *= state->release_coeff;
state->envelope = MAX(fabs(signal[i]), state->envelope);
// have current_gain go towards a desired limiter target_gain
float target_gain;
if (state->envelope > threshold)
target_gain = (1+threshold-state->envelope);
else
target_gain = 1.0;
state->current_gain = state->current_gain*state->attack_coeff +
target_gain*(1-state->attack_coeff);
// limit the delayed signal
signal[i] = delay_line[state->delay_index] * state->current_gain;
}
}
In contrast to the Python version, the delay line will be passed to the limit function. This is advantageous because now all audio buffers can be managed by Python instead of manually allocating and deallocating them in C.
Now in order to plug this code into Python I will use Cython. First of all, a "Cython header" file has to be created that declares all exported types and functions to Cython:
cdef extern from "limiter.h":
ctypedef struct limiter_state:
int delay_index
int delay_length
float envelope
float current_gain
float attack_coeff
float release_coeff
limiter_state init_limiter(float attack_factor, float release_factor, int delay_len)
void limit(float *signal, int block_length, float threshold,
float *delay_line, limiter_state *state)
This is very similar to the C header file of the limiter:
typedef struct limiter_state_t {
int delay_index;
int delay_length;
float envelope;
float current_gain;
float attack_coeff;
float release_coeff;
} limiter_state;
limiter_state init_limiter(float attack_factor, float release_factor, int delay_len);
void limit(float *signal, int block_length, float threshold,
float *delay_line, limiter_state *state);
With that squared away, the C functions are accessible for Cython. Now, we only need a small Python wrapper around this code so it becomes usable from Python:
import numpy as np
cimport numpy as np
cimport limiter
DTYPE = np.float32
ctypedef np.float32_t DTYPE_t
cdef class Limiter:
cdef limiter.limiter_state state
cdef np.ndarray delay_line
def __init__(self, float attack_coeff, float release_coeff,
int delay_length):
self.state = limiter.init_limiter(attack_coeff, release_coeff, delay_length)
self.delay_line = np.zeros(delay_length, dtype=DTYPE)
def limit(self, np.ndarray[DTYPE_t,ndim=1] signal, float threshold):
limiter.limit(<float*>np.PyArray_DATA(signal),
<int>len(signal), threshold,
<float*>np.PyArray_DATA(self.delay_line),
<limiter.limiter_state*>&self.state)
The first two lines set this file up to access Numpy arrays both from the Python domain and the C domain, thus bridging the gap. The cimport limiter imports the C functions and types from above. The DTYPE stuff is advertising the Numpy float32 type to C.
The class is defined using cdef as a C data structure for speed. Also, Cython would naturally translate every C struct into a Python dict and vice versa, but we need to pass the struct to limit and have limit modify it. Thus, cdef limiter.limiter_state state makes Cython treat it as a C struct only. Finally, the np.PyArray_DATA() expressions expose the C arrays underlying the Numpy vectors. This is really handy since we don't have to copy any data around in order to modify the vectors from C.
As can be seen, the Cython implementation behaves nearly identically to the initial Python implementation (except for passing the dtype to the constructor) and can be used as a plug-in replacement (with the aforementioned caveat).
Finally, we need to build the whole contraption. The easiest way to do this is to use a setup file like this:
from distutils.core import setup
from distutils.extension import Extension
from Cython.Distutils import build_ext
from numpy import get_include
ext_modules = [Extension("cython_limiter",
sources=["cython_limiter.pyx",
"limiter.c"],
include_dirs=['.', get_include()])]
setup(
name = "cython_limiter",
cmdclass = {'build_ext': build_ext},
ext_modules = ext_modules
)
With that saved as setup.py, python setup.py build_ext --inplace will convert the Cython code to C, and then compile both the converted Cython code and C code into a binary Python module.
Conclusion
In this article, I developed a simple limiter and how to implement it in both C and Python. Then, I showed how to use the C implementation from Python. Where the Python implementation is struggling to keep a steady frame rate going even at large block sizes, the Cython version runs smoothly down to 2-4 samples per block on a 2 Ghz Core i7. Thus, real-time audio processing is clearly feasable using Python, Cython, Numpy and PyAudio.
You can find all the source code in this article at https://github.com/bastibe/simple-cython-limiter
Disclaimer
- I invented this limiter myself. I could invent a better sounding limiter, but this article is more about how to combine Python, Numpy, PyAudio and Cython for real-time signal processing than about limiter design.
- I recently worked on something similar at my day job. They agreed that I could write about it so long as I don't divulge any company secrets. This limiter is not a descendant of any code I worked on.
- Whoever wants to use any piece of code here, feel free to do so. I am hereby placing it in the public domain. Feel free to contact me if you have questions.
Sound in Python
Have you ever wanted to work with audio data in Python? I know I do. I want to record from the microphone, I want to play sounds. I want to read and write audio files. If you ever tried this in Python, you know it is kind of a pain.
It's not for a lack of libraries though. You can read sound files using wave, SciPy provides scipy.io.wavfile, and there is a SciKit called scikits.audiolab. And except for scikits.audiolab, these return the data as raw bytes. Like, they parse the WAVE header and that is great and all, but you still have to decode your audio data yourself.
The same thing goes for playing/recording audio: PyAudio provides nifty bindings to portaudio, but you still have to decode your raw bytes by hand.
But really, what I want is something different: When I record from the microphone, I want to get a NumPy array, not bytes. You know, something I can work with! And then I want to throw that array into a sound file, or play it on a different sound card, or do some calculations on it!
So one fateful day, I was sufficiently frustrated with the state of things that I set out to create just that. Really, I only wanted to play around with cffi, but that is beside the point.
So, lets read some audio data, shall we?
import soundfile
data = soundfile.read('sad_song.wav')
done. All the audio data is now available as a NumPy array in data. Just like that.
Awesome, isn't it?
OK, that was easy. So let's read only the first and last 100 frames!
import soundfile
first = soundfile.read('long_song.flac', stop=100)
last = soundfile.read(start=-100)
This really only read the first and last bit. Not everything in between!
Note that at no point I did explicitly open or close a file! This is Python! We can do that! When the SoundFile object is created, it opens the file. When it goes out of scope, it closes the file. It's as simple as that. Or just use SoundFile in a context manager. That works as well.
Oh, but I want to use the sound card as well! I want to record audio to a file!
from pysoundcard import Stream
from pysoundfile import SoundFile, ogg_file, write_mode
with Stream() as s: # opens your default audio device
# This is supposed to be a new file, so specify it completely
f = SoundFile('happy_song.ogg', sample_rate=s.sample_rate,
channels=s.channels, format=ogg_file,
mode=write_mode)
f.write(s.read(s.sample_rate)) # one second
Read from the stream, write to a file. It works the other way round, too!
And that's really all there is to it. Working with audio data in Python is easy now!
Of course, there is much more you could do. You could create a callback function and be called every four1 frames with new audio data to process. You could request your audio data as int16, because that would be totally awesome! You could use many different sound cards at the same time, and route stuff to and fro to your hearts desire! And you can run all this on Linux using ALSA or Jack, or on Windows using DirectSound or ASIO, or on Mac using CoreAudio2. And you already saw that you can read Wave files, OGG, FLAC or MAT-files3.
You can download these libraries from PyPi, or use the binary Windows installers on Github. Or you can look at the source on Github (PySoundFile, PySoundCard), because Open Source is awesome like that! Also, you might find some bugs, because I haven't found them all yet. Then, I would like you to open an issue on Github. Or if have a great idea of how to improve things, please let me know as well.
UPDATE: It used to be that you could use indexing on SoundFile objects. For various political reasons, this is no longer the case. I updated the examples above accordingly.
You can use any block size you want. Less than 4 frames per block can be really taxing for your CPU though, so be careful or you start dropping frames.↩
More precisely: Everything that libsndfile supports.↩
Matlab and Audio Files
So I wanted to work with audio files in Matlab. In the past, Matlab could only do this with auread and wavread, which can read *.au and *.wav files. With 2012b, Matlab introduced audioread, which claims to support *.wav, *.ogg, *.flac, *.au, *.mp3, and *.mp4, and simultaneously deprecated auread and wavread.
Of these file formats, only *.au is capable of storing more than 4 Gb of audio data. But the documentation is actually wrong: audioread can actually read more data formats than documented: it reads *.w64, *.rf64, and *.caf no problem. And these can store more than 4 Gb as well.
It's just that, while audioread supports all of these nice file formats, audiowrite is more limited, and only supports *.wav, *.ogg, *.flac, and *.mp4. And it does not support any undocumented formats, either. So it seems that there is no way of writing files larger than 4 Gb. But for the time being, auwrite is still available, even though deprecated. I tried it, though, and it didn't finish writing 4.8 Gb in half an hour.
In other words, Matlab is incapable of writing audio files larger than 4 Gb. It just can't do it.
Audio APIs, Part 1: Core Audio / macOS
This is part one of a three-part series on the native audio APIs for Windows, Linux, and macOS. This first part is about Core Audio on macOS.
It has long been a major frustration for my work that Python does not have a great package for playing and recording audio. My first step to improve this situation were a small contribution to PyAudio, a CPython extension that exposes the C library PortAudio to Python. However, I soon realized that PyAudio mirrors PortAudio a bit too closely for comfort. Thus, I set out to write PySoundCard, which is a higher-level wrapper for PortAudio that tries to be more pythonic and uses NumPy arrays instead of untyped bytes buffers for audio data. However, I then realized that PortAudio itself had some inherent problems that a wrapper would not be able to solve, and a truly great solution would need to do it the hard way:
Instead of relying on PortAudio, I would have to use the native audio APIs of the three major platforms directly, and implement a simple, cross-platform, high-level, NumPy-aware Python API myself. This effort resulted in PythonAudio, a new pure-Python package that uses CFFI to talk to PulseAudio on Linux, Core Audio on macOS, and WASAPI.aspx)1 on Windows.
This series of blog posts summarizes my experiences with these three APIs and outlines the basic structure of how to use them. For reference, the singular use case in PythonAudio is playing/recording of short blocks of float data at arbitrary sampling rates and block sizes. All connected sound cards should be listable and selectable, with correct detection of the system default sound card (a feature that is very unreliable in PortAudio).
CoreAudio, or the Mac's best kept secret
CoreAudio is the native audio library for macOS. It is known for its high performance, low latency, and horrible documentation. After having used the native audio APIs on all three platforms, CoreAudio was by far the hardest one to use. The main problem is lack of documentation and lack of feedback, and plain missing or broken features. Let's get started.
The basic unit of any CoreAudio program is the audio unit. An audio unit can be a source (aka microphone), a sink (aka speaker) or an audio processor (both sink and source). Each audio unit can have several input buses, and several output buses, each of which can have several channels. The meaning of these buses varies wildly and is often underdocumented. Furthermore, every audio unit has several properties, such as a sample rate, block sizes, and a data format, and parameters, which are like properties, but presumably different in some undocumented way.
In order to use an audio unit, you create an AudioComponentDescription that describes whether you want a source or sink unit, or an effect unit, and what kind of effect you want (AudioComponent is an alternative name for audio unit). With the description, you can create an AudioComponentInstance, which is then an opaque struct pointer to your newly created audio unit. So far so good.
The next step is then to configure the audio unit using AudioUnitGetProperty and AudioUnitSetProperty. This is surprisingly hard, since every property can be configured for every bus (sometimes called element) of every input or output of every unit, and the documentation is extremely terse on which of these combinations are valid. Some invalid combinations return error codes, while others only lead to errors during playback/recording. Furthermore, the definition of what constitutes an input or output is interpreted quite differently in different places: One place calls a microphone an input, since it records audio; another place will call it an output, since it outputs audio data to the system. In one crazy example, you have to configure a microphone unit by disabling its output bus 0, and enabling its input bus 1, but then read audio data from its ostensibly disabled output bus 0.
The property interface is untyped, meaning that every property has to be given an identifier, a void pointer that points to a matching data structure, and the size of that data structure. Sometimes the setter allocates additional memory, in which case the documentation does not contain any information on who should free this memory. Most objects are passed around as opaque struct pointers with dedicated constructor and destructor functions. All of this does not strike me as particularly C-like, even though CoreAudio is supposedly a native C library.
Once your audio unit is configured, you set a render callback function, and start the audio unit. All important interaction now happens within that callback function. In a strange reversal of typical control flow, input data to the callback function needs to be fetched by calling AudioUnitRender (evoked on the unit itself) from within the callback, while output is written to memory provided as callback function arguments. Many times during development, AudioUnitRender would return error codes because of an invalid property setting during initialization. Of course, it won't tell which property is actually at fault, just that it can't fulfill the render request at the moment.
Error codes in general are a difficult topic in CoreAudio. Most functions return an error code as an OSStatus value (aka uint32), and the header files usually contain a definition of some, but not all, possible error codes. Sometimes these error codes are descriptive and nice, but often they are way too general. My favorite is the frequent kAudioUnitErr_CannotDoInCurrentContext, which is just about as useless an error description as possible. Worse, some error codes are not defined as numeric constants, but as int err = 'abcd', which makes them un-searchable in the source file. Luckily, this madness can be averted using , which is a dedicated database for
OSStatus error codes.
By far the worst part of the CoreAudio API is that some properties are silently ignored. For example, you can set the sample rate or priming information on a microphone unit, and it will accept that property change and it will report that property as changed, but it will still use its default value when recording (aka "rendering" in CoreAudio). A speaker unit, in contrast, will honor the sample rate property, and resample as necessary. If you still need to resample your microphone recordings, you have to use a separate AudioConverter unit, which is its own bag of fun (and only documented in a remark in one overview document).
Lastly, all the online documentation is written for Swift and Objective-C, while the implementation is C. Worse, the C headers contain vastly more information than the online documentation, and the online documentation often does not even reference the C header file name. Of course header files are spread into the CoreAudio framework, the AudioToolkit framework, and the AudioUnit framework, which makes even grepping a joy.
All of that said, once you know what to do and how to do it, the resulting code is relatively compact and readable. The API does contain inconsistencies and questionable design choices, but the real problem is the documentation. I spent way too much time reading the header files over and over again, and searching through (often outdated or misleading) example projects and vague high-level overviews for clues on how to interpret error messages and API documentation. I had somewhat better luck with a few blog posts on the subject, but the general consensus seems to be that the main concepts of CoreAudio are woefully under-explained, and documentation about edge cases is almost nonexistent. Needless to say, I did not enjoy my experience with CoreAudio.
WASAPI is part of the Windows Core Audio.aspx) APIs. To avoid confusion with the macOS API of the same name, I will always to refer to it as WASAPI.↩
Audio APIs, Part 2: Pulseaudio / Linux
This is part two of a three-part series on the native audio APIs for Windows, Linux, and macOS. This second part is about PulseAudio on Linux.
It has long been a major frustration for my work that Python does not have a great package for playing and recording audio. My first step to improve this situation was a small contribution to PyAudio, a CPython extension that exposes the C library PortAudio to Python. However, I soon realized that PyAudio mirrors PortAudio a bit too closely for comfort. Thus, I set out to write PySoundCard, which is a higher-level wrapper for PortAudio that tries to be more pythonic and uses NumPy arrays instead of untyped bytes buffers for audio data. However, I then realized that PortAudio itself had some inherent problems that a wrapper would not be able to solve, and a truly great solution would need to do it the hard way:
Instead of relying on PortAudio, I would have to use the native audio APIs of the three major platforms directly, and implement a simple, cross-platform, high-level, NumPy-aware Python API myself. This effort resulted in PythonAudio, a new pure-Python package that uses CFFI to talk to PulseAudio on Linux, Core Audio on macOS, and WASAPI.aspx)1 on Windows.
This series of blog posts summarizes my experiences with these three APIs and outlines the basic structure of how to use them. For reference, the singular use case in PythonAudio is block-wise playing/recording of float data at arbitrary sampling rates and block sizes. All available sound cards should be listable and selectable, with correct detection of the system default sound cards (a feature that is very unreliable in PortAudio).
PulseAudio
PulseAudio is not the only audio API on Linux. There is the grandfather OSS, the more modern ALSA, the more pro-focused JACK, and the user-focused PulseAudio. Under the hood, PulseAudio uses ALSA for its actual audio input/output, but presents the user and applications with a much nicer API and UI.
The very nice thing about PulseAudio is that it is a native C API. It provides several levels of abstraction, the highest of which takes only a handful of lines of C to get audio playing. For the purposes of PythonAudio however, I had to look at the more in-depth asynchronous API. Still, the API itself is relatively simple, and compactly defined in one simple header file.
It all starts with a mainloop and an associated context. While the mainloop is running, you can query the context for sources and sinks (aka microphones and speakers). The context can also create a stream that can be read or written (aka recorded or played). From a high level, this is all there is to it.
Most PulseAudio functions are asynchronous: Function calls return immediately, and call user-provided callback functions when they are ready to return results. While this may be a good structure for high-performance multithreaded C-code, it is somewhat cumbersome in Python. For PythonAudio, I wrapped this structure in regular Python functions that wait for the callback and return its data as normal return values.
Doing this shows just how old Python really is. Python is old-school in that it still thinks that concurrency is better solved with multiple, communicating processes, than with shared-memory threads. With such a mind set, there is a certain impedance mismatch to overcome when using PulseAudio. Every function call has to lock the main loop, and block while waiting for the callback to be called. After that, clean up by decrementing a reference count. This procedure is cumbersome, but not difficult.
What is difficult however, is the documentation. The API documentation is fine, as far as it goes. It could go into more detail with regards to edge cases and error conditions; But it truly lacks high-level overviews and examples. It took an unnecessarily long time to figure out the code path for audio playback and recording, simply because there is no document anywhere that details the sequence of events needed to get there. In the end, I followed some marginally-related example on the internet to get to that point, because the two examples provided by PulseAudio don't even use the asynchronous API.
Perhaps I am missing something, but it strikes me as strange that an API meant for audio recording and playback would not include an example that plays back and records audio.
On an application level, it can be problematic that PulseAudio seems to only value block sizes and latency requirements approximately. In particular, if computing resources become scarce, PulseAudio would rather increase latency/block sizes in the background than risk skipping. This might be convenient for a desktop application, but it is not ideal for signal processing, where latency can be crucial. It seems that I can work around these issues to an extent, but this is an inconvenience nontheless.
In general, I found PulseAudio reasonably easy to use, though. The documentation could use some work, and I don't particularly like the asynchronous programming style, but the API is simple and functional. Out of the three APIs of WASAPI/Windows, Core Audio/macOS, and PulseAudio/Linux, this one was probably the easiest to get working.
WASAPI is part of the Windows Core Audio.aspx) APIs. To avoid confusion with the macOS API of the same name, I will always to refer to it as WASAPI.↩
Audio APIs, Part 3: WASAPI / Windows
This is part three of a three-part series on the native audio APIs for Windows, Linux, and macOS. This third part is about WASAPI on Windows.
It has long been a major frustration for my work that Python does not have a great package for playing and recording audio. My first step to improve this situation was a small contribution to PyAudio, a CPython extension that exposes the C library PortAudio to Python. However, I soon realized that PyAudio mirrors PortAudio's C API a bit too closely for comfort. Thus, I set out to write PySoundCard, which is a higher-level wrapper for PortAudio that tries to be more pythonic and uses NumPy arrays instead of untyped bytes buffers for audio data. However, I then realized that PortAudio itself had some inherent problems that a wrapper would not be able to solve, and a truly great solution would need to do it the hard way:
Instead of relying on PortAudio, I would have to use the native audio APIs of the three major platforms directly, and implement a simple, cross-platform, high-level, NumPy-aware Python API myself. This effort resulted in PythonAudio, a new pure-Python package that uses CFFI to talk to PulseAudio on Linux, Core Audio on macOS, and WASAPI.aspx)1 on Windows.
This series of blog posts summarizes my experiences with these three APIs and outlines the basic structure of how to use them. For reference, the singular use case in PythonAudio is block-wise playing/recording of float data at arbitrary sampling rates and block sizes. All available sound cards should be listable and selectable, with correct detection of the system default sound cards (a feature that is very unreliable in PortAudio).
WASAPI
WASAPI is one of several native audio libraries in Windows. PortAudio actually supports five of them: Windows Multimedia (MME).aspx), the first built-in audio API for Windows 3.1x; DirectSound.aspx), the audio subsystem of DirectX for Windows 95; Windows Driver Model / Kernel Streaming (WDM/KS), the improved audio system for Windows 98; ASIO, a third-party API developed by Steinberg to make pro audio possible on Windows; and finally, Windows Audio Session API (WASAPI).aspx), introduced in Windows Vista to bring a modern audio API to Windows.
In other words, audio on Windows has a long and troubled history, and has had a lot of opportunity for experimentation. It should then be no surprise that WASAPI is a clean and well-documented audio API that avoids many of the pitfalls of its predecessors and brethren. After having experienced the audio APIs of Windows, Linux, and macOS, I am beginning to understand why some programmers love Windows.
But let's take a step back, and give an overview over the API. First of all, this is a cross-language API that is meant to be used from C#, with a solid bridge for C++, and a somewhat funky bridge for C. This is crucial to understand. The whole API is designed for a high-level, object-oriented runtime, but I am accessing it from a low-level language that has no concept of objects, methods, or exceptions.
Objects are implemented as pointers to opaque structs, with an associated list of function pointers to methods. Every method accepts the object pointer as its first argument, and returns an error value if an exception occurred. Both inputs and outputs are function arguments, with outputs being implemented as pointer-to-pointer values. While this looks convoluted to a C programmer, it is actually a very clean mapping of object oriented concepts to C that never gave me any headaches.
However, there are a few edge cases that did take me a while to understand: Since the C API is inherently not polymorphic, you sometimes have to manually specify types as cryptic UUID structs. Figuring out how to convert the UUID strings from the header files to such structs was not easy. Similarly, it took me a while to reverse-engineer that strings in Windows are actually uint16, despite being declared char. But issues such as these are to be expected in a cross-language API.
In general, I did not find a good overview on how to interpret high-level C#-concepts in C. For example, it took a long time until I learned that objects in C# are reference counted, and that I would have to manage reference counts manually. Similarly, I had one rather thorny issue with memory allocations: in rare occasions (PROPVARIANT), C# is expected to re-allocate memory of an object if the object does not have enough memory when passed into a method. This does not work as intended if you don't use C#'s memory allocator to create the memory. This was really painful to figure out.
Another result of the API's cross-language heritage are its headers: There are hundreds. And they all contain both the C API and the C++ API, separated by the occasional #ifdef __cplusplus and extern C. Worse yet, pretty much every data type and declaration is wrapped in multiple levels of preprocessor macros and typedef. There are no doubt good reasons and a rich history for this, but it took me many hours to assemble all the necessary symbols from dozens of header files to even begin to call WASAPI functions.
Nevertheless, once these hurdles are overcome, the actual WASAPI API itself is well-structured and reasonably simple. You acquire an IMMDeviceEnumerator, which returns IMMDeviceCollections for microphones and speakers. These contain IMMDevices, which represent sound cards and their properties. You activate an IMMDevice with a desired data format to get an IAudioClient, which in turns produces an IAudioRenderClient or IAudioCaptureClient for playback or recording, respectively. Playback and recording themselves are done by requesting a buffer, and reading or writing raw data to that buffer. This is about as straight-forward as APIs get.
The documentation deserves even more praise: I have rarely seen such a well-documented API. There are high-level overview articles, there is commented example code, every object is described abstractly, and every method is described in detail and in reference to related methods and example code. There is no corner case that is left undescribed, and no error code without a detailed explanation. Truly, this is exceptional documentation that is a joy to work with!
In conclusion, WASAPI leaves me in a situation I am very unfamiliar with: praising Windows. There is a non-trivial impedance mismatch between C and C# that has to be overcome to use WASAPI from C. But once I understood this, the API itself and its documentation were easy to use and understand. Impressive!
WASAPI is part of the Windows Core Audio.aspx) APIs. To avoid confusion with the macOS API of the same name, I will always to refer to it as WASAPI.↩
