Posts tagged "programming"
Names
Names are everywhere in software. We name our variables, our functions, our arguments, classes, and packages. We name our source files and the directories that contain them. We name our jar files and war files and ear files. We name and name and name. Because we do so much of it, we'd better do it well.
-- from the Introduction to chapter 2 "Meaningful Names" of "Clean Code" by Robert C. Martin.
Indeed we name a lot of things in software. As The Structure and Interpretation of Computer Programs points out, the primary purpose of a function (lambda) is to provide names for its arguments that are independent of names elsewhere. A function provides a closure in which stuff has defined names. The closure itself can then be embedded into other closures to form composite structures. Take any complex program structure and decompose its names through all its lambdas and you will only find more names right until you reach turtles.
At its heart, programming is about naming things. If I squint my eyes a little, I can nearly convince myself that naming is really all there is. All the rest is just playing games with syntax.
It's situations like this that I realize that The Structure and Interpretation of Computer Programs really changed how I view programming.
If you like programming at all, I implore you to read it, or watch it, or buy it. It really blew my mind.
Working and Learning
At the university, I have a big advantage: I can program. So many of my fellow students are programming as their main means of doing science, yet clearly never learned how to program efficiently. It is saddening to see them "fight Matlab" for days, for things that would take a programmer hours.
So how did I get to this point? After all, I went to the same university and studied the same topics they did. My first introduction to programming was our Introduction to Programming in the first semester. We learned how to write simple text-based programs in C.
My own blogging engine
At the time, my fellow students and I wanted to organize our lecture notes, copied exams, and assignments on our own website. Not knowing any better, I picked up PHP and set out to write a little website for this. It turned into a little CMS, all hand-written in PHP, HTML and (almost no) CSS.
This happened about four weeks into the introductory programming course, so I only knew a few bits of C and didn't appreciate the differences between programming languages yet. Many bad things have been said about PHP, but it allowed me to hack together a blog, file browser, gallery, and calendar with knowing little more about programming than branches and loops.
It scares me to look at the ease with which I picked up PHP at the time. With more experience, I seem to become more reluctant to try out new things. This might be a very bad thing.
C programming at the university
In my third semester, a professor offered me a job as an undergraduate research assistant. As my first assignment, he wanted me to program a MIDI interface for Matlab. The idea was to use the Matlab-C interface Mex to connect portmidi to Matlab. At this point, I had had two programming courses (C and C++_Matlab), and had read The Pragmatic Programmer.
I remember the professor telling me to stop obsessing about that piece of code. He said "You are an engineer, 95% is good enough for engineers". Yet, reading through this code now, it is some fine C code. Everything is well-commented, the implementation is clearly split into one Matlab-related part and one portmidi-related part, and there even is an (informal) test suite! To my mind, those extra 5% make an incredible difference! It is astonishing how much my early career has been influenced by The Pragmatic Programmer.
Another project concerned extending a C program that simulated small-room acoustics. It took me eight months to admit defeat. Every week, I would spend ten hours staring at my screen, trying to understand that program. Every week, I would fail in frustration. After eight months, I told the professor that I couldn't do it. A few months later, I told the professor that I would have another go at the project. This time, I read the research paper associated with the program first. After that, the project was completed in one afternoon. Sometimes, just reading the code is not enough. (This is probably more true in academia than anywhere else).
Qt and Cocoa and OpenGL
I wrote my bachelor's thesis for a small company in southern Germany. At my university, the thesis was supposed to take half a year, and should be written at some company, so students would get some first-hand experience of the real world outside the university.
The basic algorithm for the thesis was working after a few weeks. Since my boss was more interested in a commercial result than in more research, he proposed that I write a desktop application for it. This is how I was introduced to Qt. Qt is an incredibly complex framework. Luckily for me, it is also an incredibly well-documented framework! As a newcomer to programming, API docs can be a very daunting thing, filled with jargon and implementation detail. This was the first time I learned something mostly from reading the API docs, and I am grateful that I happened to pick Qt for that.
After finishing my thesis, I worked remotely for the same company, writing another GUI application. This time, the program was to be written in Objective-C/Cocoa. In contrast to Qt, I needed the book to learn Cocoa. Working through the book was a very different experience than learning Qt from API docs. The book not only described the API, but also things like best practices and programming patterns. As a result, my final program was much easier to understand and extend than the Qt program I wrote earlier.
Cocoa and Qt show two very different styles of documentation. The Qt documentation is very complete, and very well-written. It is a rare feat for a framework this complex to be learnable from the documentation alone! Doing the same thing with the Cocoa documentation instead of the book would have been painful. The book really went much further than pure API documentation can reasonably go, and my experience was better for it! (By the way, I also learned and used OpenGL during that time. The less said about the OpenGL documentation, the better).
Why Software is paid for
In the meantime, the company had been bought by a foreign investor. While this meant that my program would never see actual users, it also meant that they could offer me a proper job. And like every good engineering student, I needed Matlab, Photoshop, and Microsoft Office. And like every cliché foreign investor, they replied with "This is too expensive, here is a link to the Pirate Bay".
This did not sit well with me. After a bit of soul-searching, and my most interesting and obviously soon-deleted Stack Overflow question, I realized that I could not pirate software any longer. My own livelihood depended on people paying for the code I wrote. There was no way I would use other people's code without paying for it.
And thus we used Inkscape instead of Illustrator, and Python instead of Matlab. Mere weeks later, I discovered that Inkscape produces (mostly) standard-compatible SVG files that could be opened with any regular text editor, and manipulated with any regular XML parser! It soon became apparent that the open nature of this file format enabled us to use Inkscape for so much more than mere vector graphics! While in retrospect, it was not such a bright idea to use a vector graphics program as a GUI layout editor, it really drove home the value of open file formats and reusability! A lot of the later work on the project would have been impossible had we used Illustrator and Matlab.
Automation
We were working with a British company on a new digital mixing console at the time. Our team was mostly responsible for the software side of the project, while the British company was mostly concerned with the hardware. One big issue was that in order to get a testable system going, one had to compile some software, run some converter scripts on some files, zip some other files, set up the prototype hardware correctly, then send all the files to the prototype in the right order. Forget one step, or take an outdated version of something, and the system would not work.
It was a disaster. We would lose days debugging nonexistent issues, only because we had forgotten to update such-and-such library, or renaming some debugging file. It would be easy to blame this on my colleagues. But the reality is, no-one had ever done a project this large before, and our tools were utterly incapable of build automation of this kind.
In the end, I wrote some crazy Rube Goldberg Machine that integrated GNU make with Visual Studio, and delegated all the packaging and converting to makefiles. It would even download a large set of Unix tools and a full installation of Ruby if need be. I can't say I'm proud of this wild contraption, but anything is better than wasting days debugging non-issues. To its credit, there have been zero issues with wrongly packaged files with this system in place. I can not tell you how much stress and conflict this simple act of automation relieved. Never have a human do a machine's work.
Lua and DSLs
When I started on the job, a colleague of mine handed me a copy of "Programming for Windows 95", and told me to read it since he had modeled the internal GUI library after it. This was 2010. I was very unhappy about this. In the following years, I would rework many a subsystem within this library. But the more I changed, the more I had to take responsibility for the library. Before long, I had taken official ownership of the library, and I had to answer to questions and feature requests.
This turned out to be both a blessing and a curse. On the one hand, it gave me a great deal of freedom and authority in my own little world. On the other hand, I didn't really care for responsibility for this much legacy code in an application domain I was not particularly interested in. Thus being motivated to change things had its upsides though, and I learned a lot when implementing a font rendering engine, a bitmap caching and memory allocation system, and various configuration mechanisms on an embedded platform.
But, at the end of the day, there is only so much you can do with a bad code base in a bad subset of C++ (largely due to compilers, not people). In another slow-going week when GUI work was not particularly important, I investigated implementing a scripting layer for our framework. We were not very optimistic about this, since the scripting engine had to run on a terribly slow embedded processor that was already running almost at capacity.
We chose the scripting language Lua for the job, since it was tiny, and easy to embed (in both meanings of the word). Lua turned out to be a stellar choice! As scripting systems often go, the Lua code took over most of the frontend work in the application. Before long, all the GUI layout was done in a Lua DSL instead of XML. Imagine creating 200 buttons in a two-line for loop instead of 200 lines of XML. Also, I consider the book Programming in Lua one of the pivotal books in my programming career!
All the GUI and hardware interaction was done in Lua. The mixing console had some 40000 parameters, and a terrifying number of hardware states. I daresay that it would have been all but impossible to implement the complex interplay between all of these states in a less dynamic environment than Lua. Years later, one of the later maintainers of the product told me how this system had saved his sanity many times. This was one of the proudest moments in my career!
I vividly remember the feeling of liberation when I transitioned from C++ to Lua. I don't think we would have managed to ship the mixing console in time without Lua. In fact, there was one feature from the old analogue mixing consoles that they never managed to implement in the newer digital consoles, because it was just too hard. With Lua, it was a giant headache, but it worked. Never underestimate the power of a different language when problems seem impossibly hard.
The role of boredom in my job
The Lua experiment started in a time when work was slow, and idle thoughts had the time to mature into ideas. The system automation was started in a similar time. I was lucky to have had a few of those weeks. Some of them amounted to cool projects in the company, others I spent on improving myself.
I always had a bit of a fetish for text editing. I just love the act of feeding thoughts to the computer through a keyboard. To me, it is a much more satisfying experience than using a pencil and a sheet of paper. At the university, I used Vim on Linux, then Textmate on OS X, then XCode. On the job, I was then forced to use Visual Studio, which still holds a special place in my heart, as one of the most miserable editing experience I ever had (though Lotus Notes and Microsoft Word only rank lower because I used them less).
It should come as no surprise then, that I was overjoyed when I discovered ViEmu. It really transformed my work at the time -- what was previously a chore was now made enjoyable by the feeling of power conveyed through the Vim key bindings in Visual Studio! And this improved even further when I used another spare week to finally learn how to properly touch-type. These days, I am typing in Emacs, but enough has been written about that already.
I had one colleague who only used his two index fingers for typing. Seeing him type was maddening. But the worst thing was not his typing, but what he was not typing. Naturally, variable names were short, documentation was sparse, and code was optimized for brevity. He even resorted to some graphical code editing monstrosity, just to save himself some typing. I have written a Visual Studio tool that automatically filtered out some of the junk this tool produced, and wrote wrappers around his libraries to make them usable for other people. Seriously, don't be that guy. Typing is a core competency for any developer.
Open Source
Besides all of the GUI work I did for the company, I was actually hired for audio algorithm development. Since we didn't get a license for Matlab, I quickly grew to love Python instead. At the time, Python was right in the middle of the transition from Python 2 to Python 3, and one of the libraries I needed was Python 2 only. In another one of those fateful slow weeks, I set out to translate it to Python 3.
I didn't know much Python at the time, so the result was not exactly perfect. The maintainer of the library however was really nice about this, and helped me figuring out the problems with my code. This was the first time I ever talked to any programmer outside my company! And even better, this programmer seemed to be a professor at MIT, or something, and likely a lot more experienced and intelligent than I was! I was incredibly lucky that this first contact with the open source world was such a kind and positive one.
Not too long after that, I started writing my own open source libraries, and publishing them on the web. And before too long, people began using those projects! And then they started contributing to them as well! In a way, one of my main griefs with working for a company has always been that there are so few people with which you can talk about the things you do all day. And now, suddenly, random people from all over the world are showing interest and help for the things I do in my spare time! I really can't emphasize enough how much this involvement with the open source community and other people has improved my view of the world, and my understanding of the work I do!
My next adventure
This has been a summary of the things I did so far. It has been an incredible journey, and one that never stopped to surprise me. Now I am finishing my master's thesis, and getting ready for a doctorate after that. All the work I did and do is based on the incredible work of people before me. At least for the time being, I want this to be the goal of my further work: To advance the sum total knowledge of the world, if only by a tiny bit.
For this, my most important tool is still programming. Learning how to program is an immensely valuable skill, and doubly so if your job title is not "developer" or "programmer". Programming is not just a tool to talk to the computer and earn a living. We should not forget that programming is also a rich thinking tool for trying out new ideas, and sharing them with other people.
For the moment, I have no desire for being beholden to some company dictating my goals and hiding my achievements. Writing this up has proven to be a very liberating and insightful experience for myself, just the way my research journal is for my day-to-day work. Putting ideas and algorithms in writing is an incredibly useful tool for finding one's place in the world and contributing to its betterment!
Julia First Impressions
Julia is a high-level dynamic programming language designed to address the requirements of high-performance numerical and scientific computing while also being effective for general purpose programming. —Wikipedia
In other words, it is supposed to be as fast as C, as practical as Python, and as scientific as Matlab. The next step in mainstream scientific computing.
However, Julia is still very young, and still evolving rapidly. But if any of the above is true, I am very interested!
So, over the last few days, I re-implemented an algorithm in Julia. The previous version of the algorithm was written in Python. The algorithm spends most of it's time in FFTs, thus I didn't expect big performance gains.
It is actually nice to have a language that is built for scientific computation. Coming from Python, it is refreshing to have array literals, ranges and mathematics available without importing anything. Much like Python, Julia also has a proper module system, comprehensions, and more than one function per file.
On the other hand, there are a few questionable design decisions as well. Julia uses 1-based, inclusive indexing (range[1:3] = [1 2 3] as opposed to Python's range[:3] = [0, 1, 2]). In practice, my experience is that I rarely need to add ±1 when indexing in Python, but I frequently need it in Julia/Matlab.
Also, Julia has no docstrings, which makes me sad. The whole documentation story is sad, really: Documentation is often incomplete, or missing altogether. Unit testing is not widespread at all, and still crude. 0.4 will apparently add docstrings using macros. This is ugly and doesn't work for one's own code, but it's certainly a step in the right direction. Those error messages would need some work, too.
All of that is hopefully just a symptom of Julia being young, and will improve over time. Similarly, signal processing functions are missing entirely, and I had to re-implement some. The community is growing rapidly, though, and a lot of missing functionality can be installed through the package manager already.
When it comes to writing code, there is a lot to like about Julia. Julia's type system does impose a bit of overhead, but it also grants immediate benefits: Many of Python's runtime errors happen at evaluation time and functions can easily document their arguments' types. Also, thinking strictly about types actually improved performance by a good 20% in my algorithm.
And finally, Performance is surprisingly good! Although my algorithm spends almost all of its time doing FFTs, Julia performed about twice as fast as Python. This is pretty much exactly twice as much as I had expected! It also exposed more of the features of the underlying libraries, which could be used for another speed-up of some 10%.
At the end of the day, Julia clearly isn't mature yet, but very promising. Documentation and libraries will no doubt grow, and performance is already excellent. I'll definitely keep an eye on it, and will experiment further when the opportunity presents itself.
Changing File Creation Dates in OSX
On my last vacation, I have taken a bunch of pictures, and a bunch of video. The problem is, I hadn't used the video camera in a long time, and it believed that all it's videos were taken on the first of January 2012. So in order for the pictures to show up correctly in my picture library, I wanted to correct that.
For images, this is relatively easy: Most picture libraries support some kind of bulk date changes, and there are a bunch of command line utilities that can do it, too. But none of these tools work for video (exiftool claims be able to do that, but I couldn't get it to work).
So instead, I went about to change the file creation date of the actual video files. And it turns out, this is surprisingly hard! The thing is, most Unix systems (a Mac is technically a Unix system) don't even know the concept of a file creation date. Thus, most Unix utilities, including most programming languages, don't know how to deal with that, either.
If you have XCode installed, this will come with SetFile, a command line utility that can change file creation dates. Note that SetFile can change either the file creation date, or the file modification date, but not both at the same time, as any normal Unix utility would. Also note that SetFile expects dates in American notation, which is about as nonsensical as date formats come.
Anyway, here's a small Python script that changes the file creation date (but not the time) of a bunch of video files:
import os.path
import os
import datetime
# I want to change the dates on the files GOPR0246.MP4-GOPR0264.MP4
for index in range(426, 465):
filename = 'GOPR0{}.MP4'.format(index)
# extract old date:
date = datetime.datetime.fromtimestamp(os.path.getctime(filename))
# create a new date with the same time, but on 2015-08-22
new_date = datetime.datetime(2015, 8, 22, date.hour, date.minute, date.second)
# set the file creation date with the "-d" switch, which presumably stands for "dodification"
os.system('SetFile -d "{}" {}'.format(new_date.strftime('%m/%d/%Y %H:%M:%S'), filename))
# set the file modification date with the "-m" switch
os.system('SetFile -m "{}" {}'.format(new_date.strftime('%m/%d/%Y %H:%M:%S'), filename))
The Style of Scientific Code
What does quality code look like? One common school of thought focuses on small, descriptive functions that take few arguments. To quote from Clean Code: "The first rule of functions is that they should be small", on the order of less than ten lines. "Functions should not be large enough to hold nested structures". "The ideal number of arguments for a function is zero [, one, or two]. Three [or more] arguments should be avoided where possible".
A few years ago, when I was working mostly on user interaction and data management, all of this made sense to me. What is the overhead of a few function calls and class lookups here and there if it makes the code more readable? In other words: Readability counts, and is usually more important than performance.
But lately, I have come to struggle with these rules. I am now writing a lot of scientific code, where algorithms are intrinsically complex beyond the syntactic complexity of the code. How do you "Express yourself in code [instead of comments]", when that code only consists of linear algebra and matrix multiplications?
def rectwin_spectrum(angular_frequency, specsize):
"""The spectrum of a rectangular window. [...]"""
# In case of angular_frequency == 0, this will calculate NaN. Since
# this will be corrected later, suppress the warning.
with np.errstate(invalid='ignore'):
spectrum = ( np.exp(-1j*angular_frequency*(specsize-1)/2) *
np.sin(specsize*angular_frequency/2) /
np.sin(angular_frequency/2) )
# since sin(x) == x for small x, the above expression
# evaluates to specsize for angular_frequency == 0.
spectrum[angular_frequency == 0.0] = specsize
return spectrum
A lot of my scientific code ends up quite compact like that. Maybe a hundred lines of dense numeric expressions, plus a few hundred lines of explanations and documentation. The point is, scientific code often does not decompose into easily understood extractable functions.
On a related issue, how do you avoid long argument lists in heavily parametrized equations? As Clean Code states, "when a function seems to need more than two or three arguments, it is likely that some of those arguments ought to be wrapped in a class of their own". However, in Matlab in particular, it is quite unusual to create small one-trick classes to encapsulate a few function arguments:
classdef SignalBlocks < handle
properties
data
samplerate
blocksize
hopsize
end
properties (Dependent)
duration
end
methods
function obj = SignalBlock(data, samplerate, blocksize, hopsize)
% blocksize and hopsize are optional. What a mess.
narginchk(2, 4);
obj.data = data;
obj.samplerate = samplerate;
if nargin >= 3
obj.blocksize = blocksize;
else
obj.blocksize = 2048;
end
if nargin == 4
obj.hopsize = hopsize;
else
obj.hopsize = 1024;
end
end
function time = get.duration(obj)
time = length(obj.data)/obj.samplerate;
end
end
end
This is not just cumbersome to write and maintain, it is also slower than passing data, samplerate, blocksize, and hopsize to each function call individually (although the overhead has gotten considerably smaller in newer versions of Matlab). Additionally, there is often a large performance benefit of not extracting every function and not keeping intermediate values in variables. Thus, it's not just readability that is hard to maintain in scientific code. Performance is a problem, too.
The sad thing is, I don't know the answer to these questions. There have been a lot of discussions about coding style and code quality in our department lately, with the clear objective to clean up our code. But common code quality criteria don't seem to apply to scientific code all that well.
Do you have any idea how to progress from here?
Scientific Code
A short while ago, I spent a few weeks collecting and evaluating various implementations of speech analysis algorithms for my current work. TL;DR: the general quality of scientific software is bad, and needs to improve.
Let me state up front that I am explicitly not talking about the quality of the science itself. This blog post is exclusively focused on the published software. In general, the problems were bad programming, old and unmaintained code, and lack of documentation. While none of these things mean bad science, they are a real challenge to reproducibility. Follow-up work can not quote algorithms they can't run.
Most scientists are not programmers, and use programming as a tool for doing science. Scientists typically don't conceptualize algorithms as code, and don't reason about their implementation in terms of code. Consequently, executable implementations tend to not read like code, either. And frankly, this is as it should be. In my area of research, programming abstractions are not a great medium for expressing scientific ideas, and programming transformations are weak in comparison to mathematical operations.
Still, the result is bad code. And bad code is a problem for reproducibility and comparability. Scientists therefore need to produce better code that is readable and portable. Straight-up letter-by-letter translations of the published math is just not enough, with all its single-letter variable names and complex nested expressions. We have to do better.
Include an Example Script
I have seen many instances of code that clearly worked at one point on the original author's machine, but doesn't on my computer. Maybe that is because I am running a different version of the programming environment, maybe my data is subtly different, maybe the author forgot to document a dependency. All of these happened to me, and all of these are exactly what you would expect from old, unmaintained code from non-expert programmers.
The least we can do to improve this situation, is to document how the code was supposed to work. A simple example script with example data and example results lets me verify that the code does what it is supposed to be doing. Without this, I can not diagnose errors. Worse, if no example results are included, I might conclude that the algorithm was bad, when in reality I was simply using an incorrect version of a dependency.
Document Dependencies
It is important to document all toolboxes, libraries, and programming languages used, including their exact version and operating system. At one point, I spent several hours debugging some Java code that worked in Java 5, but didn't on any recent Java version. If this had been documented, I could have fixed that error much more quickly. In another case, one piece of C code contained a subtle error if compiled with a 64 bit compiler. Again, this took a long time to track down, and would have been much easier if the original operating system and compiler version had been documented.
That same piece of C code could only be run by compiling several library dependency from old versions of their source code. In that case, the author helpfully included copies of the original source code for these libraries with his source distribution. Without that, I would never have gotten that piece of code to run!
Also, if at all possible, published code should use as few dependencies as possible. Not only might I not have access to that fancy Matlab Toolbox, but every step in the installation instructions is another thing that can go wrong. The more contained the code, the more likely it is that it will still be executable many years later.
Higher Level Languages are better than Lower Level Languages
In general, I had far less problems with non-compiled, high-level code for Matlab, Python, or R, than with low-level C or Java code. On the one hand, this is a technological problem: It is easier to keep an interpreter compatible with outdated code than it is to keep a more complex tool chains with compilers, linkers, and runtime libraries compatible. On the other hand though, this is a human problem as well: I happen to know Python, Matlab, and C pretty well, but I don't know much R or Java. Still, it is much easier to reason about the runtime behavior of R code (because I can inspect variables like in any other dynamic programming language) than to debug some unknown build tool interaction in Java (because compilation tool chains are typically much more complex and variable than REPLs).
Keep it Simple
A particular problem are compiled modules for an interpreted language. Such Mex files and CPython extensions are almost guaranteed to break when programming language versions change, and are often hard to upgrade, since the C APIs often change with the language version as well. Often, these compiled modules are provided for performance reasons. But what was painfully slow on the original author's work laptop a few years ago might not be a problem at all on a future compute cluster. If the code absolutely has to be provided a Mex file or a CPython extension, we should at least provide an interpreted version as well.
And speaking of compute clusters, I have had a lot of trouble with clever tricks such as massively parallelized code or GPU-optimized code. Not only does this age poorly, it also wreaks havoc when trying to run this code on a compute cluster. Such low-level performance optimizations are rarely a good idea for published scientific code, and should at least be optional and well-documented.
Document the Code
Code is never self-documenting. Given enough time, entropy increases inexorably, and times change. Conventions change, and what seemed obvious a few years ago might look like gibberish today. What is perfectly readable to a domain expert is inscrutable even to scientists of closely related areas of research. It is therefore necessary to always document published code, even if the code looks perfectly obvious to the author. In the same vein, we should refrain from using jargon in our code, and clearly declare our variables and invariants (they are bound to be different for different people).
Importantly, this includes documenting all file formats and data structures. Institutions often have in-house standards for how to represent certain kinds of data, and practitioners don't realize that these conventions are not followed universally. I had to ignore a few apparently high-quality algorithms simply because I could not figure out how to supply data to their code. For many other algorithms, I had to write custom data exporters and data importers. Again, an algorithm won't get quoted if it can't be run.
Make it Automatable
Another thing I see frequently are very fancy graphical user interfaces for scientific code. The only thing that breaks faster than compiled language extensions are GUI programs. GUIs are necessarily complex, and therefore hard to debug. And worse yet, if the code can only be run in a GUI, it can't be automated, and I won't be able to compare its performance in a big experiment with hundreds of runs. In effect, GUIs make an algorithm non-reproducible. If a GUI needs to be included in the code, it should at least be made optional.
Do Release Code
However, more importantly than anything I said so far: Do release source code for your algorithm. Nothing is more wasteful than reading about an amazing algorithm that I can't try out. If no source code is released, it is not reproducible, it can't be compared to other algorithms in the field, and it might as well not have been published.
Audio APIs, Part 1: Core Audio / macOS
This is part one of a three-part series on the native audio APIs for Windows, Linux, and macOS. This first part is about Core Audio on macOS.
It has long been a major frustration for my work that Python does not have a great package for playing and recording audio. My first step to improve this situation were a small contribution to PyAudio, a CPython extension that exposes the C library PortAudio to Python. However, I soon realized that PyAudio mirrors PortAudio a bit too closely for comfort. Thus, I set out to write PySoundCard, which is a higher-level wrapper for PortAudio that tries to be more pythonic and uses NumPy arrays instead of untyped bytes buffers for audio data. However, I then realized that PortAudio itself had some inherent problems that a wrapper would not be able to solve, and a truly great solution would need to do it the hard way:
Instead of relying on PortAudio, I would have to use the native audio APIs of the three major platforms directly, and implement a simple, cross-platform, high-level, NumPy-aware Python API myself. This effort resulted in PythonAudio, a new pure-Python package that uses CFFI to talk to PulseAudio on Linux, Core Audio on macOS, and WASAPI.aspx)1 on Windows.
This series of blog posts summarizes my experiences with these three APIs and outlines the basic structure of how to use them. For reference, the singular use case in PythonAudio is playing/recording of short blocks of float data at arbitrary sampling rates and block sizes. All connected sound cards should be listable and selectable, with correct detection of the system default sound card (a feature that is very unreliable in PortAudio).
CoreAudio, or the Mac's best kept secret
CoreAudio is the native audio library for macOS. It is known for its high performance, low latency, and horrible documentation. After having used the native audio APIs on all three platforms, CoreAudio was by far the hardest one to use. The main problem is lack of documentation and lack of feedback, and plain missing or broken features. Let's get started.
The basic unit of any CoreAudio program is the audio unit. An audio unit can be a source (aka microphone), a sink (aka speaker) or an audio processor (both sink and source). Each audio unit can have several input buses, and several output buses, each of which can have several channels. The meaning of these buses varies wildly and is often underdocumented. Furthermore, every audio unit has several properties, such as a sample rate, block sizes, and a data format, and parameters, which are like properties, but presumably different in some undocumented way.
In order to use an audio unit, you create an AudioComponentDescription that describes whether you want a source or sink unit, or an effect unit, and what kind of effect you want (AudioComponent is an alternative name for audio unit). With the description, you can create an AudioComponentInstance, which is then an opaque struct pointer to your newly created audio unit. So far so good.
The next step is then to configure the audio unit using AudioUnitGetProperty and AudioUnitSetProperty. This is surprisingly hard, since every property can be configured for every bus (sometimes called element) of every input or output of every unit, and the documentation is extremely terse on which of these combinations are valid. Some invalid combinations return error codes, while others only lead to errors during playback/recording. Furthermore, the definition of what constitutes an input or output is interpreted quite differently in different places: One place calls a microphone an input, since it records audio; another place will call it an output, since it outputs audio data to the system. In one crazy example, you have to configure a microphone unit by disabling its output bus 0, and enabling its input bus 1, but then read audio data from its ostensibly disabled output bus 0.
The property interface is untyped, meaning that every property has to be given an identifier, a void pointer that points to a matching data structure, and the size of that data structure. Sometimes the setter allocates additional memory, in which case the documentation does not contain any information on who should free this memory. Most objects are passed around as opaque struct pointers with dedicated constructor and destructor functions. All of this does not strike me as particularly C-like, even though CoreAudio is supposedly a native C library.
Once your audio unit is configured, you set a render callback function, and start the audio unit. All important interaction now happens within that callback function. In a strange reversal of typical control flow, input data to the callback function needs to be fetched by calling AudioUnitRender (evoked on the unit itself) from within the callback, while output is written to memory provided as callback function arguments. Many times during development, AudioUnitRender would return error codes because of an invalid property setting during initialization. Of course, it won't tell which property is actually at fault, just that it can't fulfill the render request at the moment.
Error codes in general are a difficult topic in CoreAudio. Most functions return an error code as an OSStatus value (aka uint32), and the header files usually contain a definition of some, but not all, possible error codes. Sometimes these error codes are descriptive and nice, but often they are way too general. My favorite is the frequent kAudioUnitErr_CannotDoInCurrentContext, which is just about as useless an error description as possible. Worse, some error codes are not defined as numeric constants, but as int err = 'abcd', which makes them un-searchable in the source file. Luckily, this madness can be averted using , which is a dedicated database for
OSStatus error codes.
By far the worst part of the CoreAudio API is that some properties are silently ignored. For example, you can set the sample rate or priming information on a microphone unit, and it will accept that property change and it will report that property as changed, but it will still use its default value when recording (aka "rendering" in CoreAudio). A speaker unit, in contrast, will honor the sample rate property, and resample as necessary. If you still need to resample your microphone recordings, you have to use a separate AudioConverter unit, which is its own bag of fun (and only documented in a remark in one overview document).
Lastly, all the online documentation is written for Swift and Objective-C, while the implementation is C. Worse, the C headers contain vastly more information than the online documentation, and the online documentation often does not even reference the C header file name. Of course header files are spread into the CoreAudio framework, the AudioToolkit framework, and the AudioUnit framework, which makes even grepping a joy.
All of that said, once you know what to do and how to do it, the resulting code is relatively compact and readable. The API does contain inconsistencies and questionable design choices, but the real problem is the documentation. I spent way too much time reading the header files over and over again, and searching through (often outdated or misleading) example projects and vague high-level overviews for clues on how to interpret error messages and API documentation. I had somewhat better luck with a few blog posts on the subject, but the general consensus seems to be that the main concepts of CoreAudio are woefully under-explained, and documentation about edge cases is almost nonexistent. Needless to say, I did not enjoy my experience with CoreAudio.
WASAPI is part of the Windows Core Audio.aspx) APIs. To avoid confusion with the macOS API of the same name, I will always to refer to it as WASAPI.↩
Audio APIs, Part 2: Pulseaudio / Linux
This is part two of a three-part series on the native audio APIs for Windows, Linux, and macOS. This second part is about PulseAudio on Linux.
It has long been a major frustration for my work that Python does not have a great package for playing and recording audio. My first step to improve this situation was a small contribution to PyAudio, a CPython extension that exposes the C library PortAudio to Python. However, I soon realized that PyAudio mirrors PortAudio a bit too closely for comfort. Thus, I set out to write PySoundCard, which is a higher-level wrapper for PortAudio that tries to be more pythonic and uses NumPy arrays instead of untyped bytes buffers for audio data. However, I then realized that PortAudio itself had some inherent problems that a wrapper would not be able to solve, and a truly great solution would need to do it the hard way:
Instead of relying on PortAudio, I would have to use the native audio APIs of the three major platforms directly, and implement a simple, cross-platform, high-level, NumPy-aware Python API myself. This effort resulted in PythonAudio, a new pure-Python package that uses CFFI to talk to PulseAudio on Linux, Core Audio on macOS, and WASAPI.aspx)1 on Windows.
This series of blog posts summarizes my experiences with these three APIs and outlines the basic structure of how to use them. For reference, the singular use case in PythonAudio is block-wise playing/recording of float data at arbitrary sampling rates and block sizes. All available sound cards should be listable and selectable, with correct detection of the system default sound cards (a feature that is very unreliable in PortAudio).
PulseAudio
PulseAudio is not the only audio API on Linux. There is the grandfather OSS, the more modern ALSA, the more pro-focused JACK, and the user-focused PulseAudio. Under the hood, PulseAudio uses ALSA for its actual audio input/output, but presents the user and applications with a much nicer API and UI.
The very nice thing about PulseAudio is that it is a native C API. It provides several levels of abstraction, the highest of which takes only a handful of lines of C to get audio playing. For the purposes of PythonAudio however, I had to look at the more in-depth asynchronous API. Still, the API itself is relatively simple, and compactly defined in one simple header file.
It all starts with a mainloop and an associated context. While the mainloop is running, you can query the context for sources and sinks (aka microphones and speakers). The context can also create a stream that can be read or written (aka recorded or played). From a high level, this is all there is to it.
Most PulseAudio functions are asynchronous: Function calls return immediately, and call user-provided callback functions when they are ready to return results. While this may be a good structure for high-performance multithreaded C-code, it is somewhat cumbersome in Python. For PythonAudio, I wrapped this structure in regular Python functions that wait for the callback and return its data as normal return values.
Doing this shows just how old Python really is. Python is old-school in that it still thinks that concurrency is better solved with multiple, communicating processes, than with shared-memory threads. With such a mind set, there is a certain impedance mismatch to overcome when using PulseAudio. Every function call has to lock the main loop, and block while waiting for the callback to be called. After that, clean up by decrementing a reference count. This procedure is cumbersome, but not difficult.
What is difficult however, is the documentation. The API documentation is fine, as far as it goes. It could go into more detail with regards to edge cases and error conditions; But it truly lacks high-level overviews and examples. It took an unnecessarily long time to figure out the code path for audio playback and recording, simply because there is no document anywhere that details the sequence of events needed to get there. In the end, I followed some marginally-related example on the internet to get to that point, because the two examples provided by PulseAudio don't even use the asynchronous API.
Perhaps I am missing something, but it strikes me as strange that an API meant for audio recording and playback would not include an example that plays back and records audio.
On an application level, it can be problematic that PulseAudio seems to only value block sizes and latency requirements approximately. In particular, if computing resources become scarce, PulseAudio would rather increase latency/block sizes in the background than risk skipping. This might be convenient for a desktop application, but it is not ideal for signal processing, where latency can be crucial. It seems that I can work around these issues to an extent, but this is an inconvenience nontheless.
In general, I found PulseAudio reasonably easy to use, though. The documentation could use some work, and I don't particularly like the asynchronous programming style, but the API is simple and functional. Out of the three APIs of WASAPI/Windows, Core Audio/macOS, and PulseAudio/Linux, this one was probably the easiest to get working.
WASAPI is part of the Windows Core Audio.aspx) APIs. To avoid confusion with the macOS API of the same name, I will always to refer to it as WASAPI.↩
Audio APIs, Part 3: WASAPI / Windows
This is part three of a three-part series on the native audio APIs for Windows, Linux, and macOS. This third part is about WASAPI on Windows.
It has long been a major frustration for my work that Python does not have a great package for playing and recording audio. My first step to improve this situation was a small contribution to PyAudio, a CPython extension that exposes the C library PortAudio to Python. However, I soon realized that PyAudio mirrors PortAudio's C API a bit too closely for comfort. Thus, I set out to write PySoundCard, which is a higher-level wrapper for PortAudio that tries to be more pythonic and uses NumPy arrays instead of untyped bytes buffers for audio data. However, I then realized that PortAudio itself had some inherent problems that a wrapper would not be able to solve, and a truly great solution would need to do it the hard way:
Instead of relying on PortAudio, I would have to use the native audio APIs of the three major platforms directly, and implement a simple, cross-platform, high-level, NumPy-aware Python API myself. This effort resulted in PythonAudio, a new pure-Python package that uses CFFI to talk to PulseAudio on Linux, Core Audio on macOS, and WASAPI.aspx)1 on Windows.
This series of blog posts summarizes my experiences with these three APIs and outlines the basic structure of how to use them. For reference, the singular use case in PythonAudio is block-wise playing/recording of float data at arbitrary sampling rates and block sizes. All available sound cards should be listable and selectable, with correct detection of the system default sound cards (a feature that is very unreliable in PortAudio).
WASAPI
WASAPI is one of several native audio libraries in Windows. PortAudio actually supports five of them: Windows Multimedia (MME).aspx), the first built-in audio API for Windows 3.1x; DirectSound.aspx), the audio subsystem of DirectX for Windows 95; Windows Driver Model / Kernel Streaming (WDM/KS), the improved audio system for Windows 98; ASIO, a third-party API developed by Steinberg to make pro audio possible on Windows; and finally, Windows Audio Session API (WASAPI).aspx), introduced in Windows Vista to bring a modern audio API to Windows.
In other words, audio on Windows has a long and troubled history, and has had a lot of opportunity for experimentation. It should then be no surprise that WASAPI is a clean and well-documented audio API that avoids many of the pitfalls of its predecessors and brethren. After having experienced the audio APIs of Windows, Linux, and macOS, I am beginning to understand why some programmers love Windows.
But let's take a step back, and give an overview over the API. First of all, this is a cross-language API that is meant to be used from C#, with a solid bridge for C++, and a somewhat funky bridge for C. This is crucial to understand. The whole API is designed for a high-level, object-oriented runtime, but I am accessing it from a low-level language that has no concept of objects, methods, or exceptions.
Objects are implemented as pointers to opaque structs, with an associated list of function pointers to methods. Every method accepts the object pointer as its first argument, and returns an error value if an exception occurred. Both inputs and outputs are function arguments, with outputs being implemented as pointer-to-pointer values. While this looks convoluted to a C programmer, it is actually a very clean mapping of object oriented concepts to C that never gave me any headaches.
However, there are a few edge cases that did take me a while to understand: Since the C API is inherently not polymorphic, you sometimes have to manually specify types as cryptic UUID structs. Figuring out how to convert the UUID strings from the header files to such structs was not easy. Similarly, it took me a while to reverse-engineer that strings in Windows are actually uint16, despite being declared char. But issues such as these are to be expected in a cross-language API.
In general, I did not find a good overview on how to interpret high-level C#-concepts in C. For example, it took a long time until I learned that objects in C# are reference counted, and that I would have to manage reference counts manually. Similarly, I had one rather thorny issue with memory allocations: in rare occasions (PROPVARIANT), C# is expected to re-allocate memory of an object if the object does not have enough memory when passed into a method. This does not work as intended if you don't use C#'s memory allocator to create the memory. This was really painful to figure out.
Another result of the API's cross-language heritage are its headers: There are hundreds. And they all contain both the C API and the C++ API, separated by the occasional #ifdef __cplusplus and extern C. Worse yet, pretty much every data type and declaration is wrapped in multiple levels of preprocessor macros and typedef. There are no doubt good reasons and a rich history for this, but it took me many hours to assemble all the necessary symbols from dozens of header files to even begin to call WASAPI functions.
Nevertheless, once these hurdles are overcome, the actual WASAPI API itself is well-structured and reasonably simple. You acquire an IMMDeviceEnumerator, which returns IMMDeviceCollections for microphones and speakers. These contain IMMDevices, which represent sound cards and their properties. You activate an IMMDevice with a desired data format to get an IAudioClient, which in turns produces an IAudioRenderClient or IAudioCaptureClient for playback or recording, respectively. Playback and recording themselves are done by requesting a buffer, and reading or writing raw data to that buffer. This is about as straight-forward as APIs get.
The documentation deserves even more praise: I have rarely seen such a well-documented API. There are high-level overview articles, there is commented example code, every object is described abstractly, and every method is described in detail and in reference to related methods and example code. There is no corner case that is left undescribed, and no error code without a detailed explanation. Truly, this is exceptional documentation that is a joy to work with!
In conclusion, WASAPI leaves me in a situation I am very unfamiliar with: praising Windows. There is a non-trivial impedance mismatch between C and C# that has to be overcome to use WASAPI from C. But once I understood this, the API itself and its documentation were easy to use and understand. Impressive!
WASAPI is part of the Windows Core Audio.aspx) APIs. To avoid confusion with the macOS API of the same name, I will always to refer to it as WASAPI.↩
The Long Game
Here's a thing I do: I write open source libraries that solve my problems. Bad libraries. And then, over the course of a year or two, I slowly improve them, until they are not so bad any more.
I have gone through this pattern a few times now. SoundFile started out buggy and slow. Transplant crashed and froze very often. Org-Journal deleted journal entries every now and then. But then users found errors, and errors were fixed. And slowly, over time, these libraries transformed from buggy prototypes into dependable tools. After a year or so, I saw Github Issues gradually drying up, and feedback changing from "X is broken" to "How can I do X?". It is an oddly gratifying process.
Interestingly though, I rarely hear people talking about this, that building a thing is only the beginning, and the meat of open source development is sticking with it for a long time, and gradually, slowly, weeding out the bugs. All great open source libraries I know evolved this way, yet it is rarely written about.
Playing the long game means anticipating and managing the amount of maintenance I am going to do on a project. When releasing a new library, the first few months and users will shake out bugs, and create work for the maintainers. This can be a dangerous source of stress and anxiety. I've had my brush with burnout in the past, and my only defense to this is to be honest about my availability. Often, this means stating outright that I probably won't have the time to work on a thing.
However, I have also learned that it is OK to defer issues to the future. There have been many problems that I didn't have the time to address when they first came up, but did address a few months later, probably in response to a separate bug report. Important problems have a way of getting fixed eventually. Other times, a solution just takes a long time to mature. There have been multiple issues that lay dormant for months until I stumbled upon a good solution.
And good solutions are important for open source software: If a bug fix adds too much complexity, it will inevitably lead to more bugs. This can easily snowball into a situation where each hour I invest into a project creates more hours of future maintenance burden. A situation like this feels hopeless and terrible. It feels like work. It is therefore important for my sanity to control the complexity of my projects, even if that means not adding features or not addressing problems. Open source development is not beholden to the dollar sign, and gives you the freedom to do it right.
This is not universally understood by programmers or users. And it doesn't just involve technical questions: Some users have expected me to provide commercial-grade support, and got surprisingly unpleasant when I didn't. But it is crucial to realize that publishing open source software does not imply an obligation to fix every issue right now. Quite on the contrary, many open source developers necessarily work on their own schedule, and part of the enjoyment of open source development is derived from this exact freedom!
At this point, my Github lists a bunch of open source projects. Some of them have gotten attention, which lead to bug reports, and, over time, let them grow to maturity. Some turned out to be useful to me, but not to others. Some are useful to others, but not to me. Some turned out to be not useful at all, and are now largely abandoned. And some of them, like RunForrest and SoundCard, are still new and raw and terrible, but will mature over time.
That's a thing I do: I write open source libraries. Good libraries, but as a wise man once said "When you feel how depressingly / slowly you climb, / it's well to remember that / Things Take Time". Working on open source grants you this freedom, and is joyful for it.
Files and Processes
In the last few months, I have created three notable programming projects: RunForrest saves function call graphs to disk and runs them in parallel processes; TimeUp creates backups using rsync and keeps different numbers of hourly, daily, and weekly backups; and JBOF, which organizes large collections of data and metadata as structured, on-disk datasets.
These projects have one thing in common: They use Python to interact with external things, such as files, libraries, or processes. It surprised me that none of these projects were particularly hard to build, even though they accomplish "hard" tasks. This prompted some soul-searching about why I thought these tasks to be hard, and I have come up with two observations:
Files and processes are considered "not part of the language", and are therefore not taught. Most programming classes and programming tutorials I have seen focus on the internals of a programming language, i.e. its data structures, and built-in functions and libraries. Files and processes are not part of this, and are often only mentioned in passing, as a thing that a particularly library can do. Worse, many curricula never formally explain files or processes, or their use in building programs.
I now believe that this is unfortunate and misguided, since the interaction with the computer's resources is the central benefit of programming, and you can not make much use of those resources without a thorough understanding of files and processes. In a way, the "inside" of a programming language is a mere sandbox, a safe place for toying with imaginary castles. But it is the "outside", that is, external programs, libraries, and files, that unlocks the true power of making the computer do work. And in Python in particular, using these building blocks to build useful programs is surprisingly simple.
However, such small and simple programs are much less popular than bloated behemoths. I built RunForrest explicitly because Dask was too confusing and unpredictable for the job. I build JBOF because h5py was too complex and slow. And this is surprising, since these tools certainly are vastly more mature than anything I can whip up. But they were developed by large organizations to solve large-organization problems. But I am not a large organization, and my needs are different as well.
I now believe that such small-scale solutions are often preferable to high-profile tools, but they lack the visibility and publicity of tools such as Dask and HDF. And even worse, seeing these big tools solve such mundane problems, we form the belief that these problems must be incredibly complex, and beyond our abilities. Thus forms a vicious cycle. Of course, this is not to say that these big tools do not serve a purpose. Dask and HDF were built to solve particular problems, but we should be aware that most big tools were built for big problems, and our own problems are often not big enough to warrant their use.
In summary, we should teach people about files and processes, and empower them to tackle "hard" tasks without resorting to monolithic libraries. Not only is this incredibly satisfying, it also leads to better programs and better programmers.
Dealing with Unreliable Software
About a year ago, I started working on a big comparison study between a bunch of scientific algorithms. Many of these have open-source software available, and I wanted to evaluate them with a large variety of input signals. The problem is, this is scientific code, i.e. the worst code imaginable.
Things this code has done to my computer:
- it crashed, throwing an error, and shutting down nicely
- it crashed with a segfault, taking the owning process with it
- it crashed, leaving temporary files lying around
- it crashed, leaving zombie processes lying around
- it spin-locked, and never returned
- it spin-locked, and forked uncontrollably until all process decriptors were exhausted
- it spin-locked, and ate memory uncontrollably until all memory was consumed
- it crashed other, unrelated programs (no idea how it managed that)
- it corrupted the root file system (no idea how it managed that)
Note that the code did not do any of this intentionally. It was merely code written by non-expert programmers, the problems often a side effect of performance optimizations. The code mostly works fine if called only once or twice. My problems only become apparent if I ran it, say, a few hundred thousand times, with dozens of processes in parallel.
So, how do you deal with this? Multi-threading is not an option, since a segfault would kill the whole program. So it has to be multi-processing. But all the multi-processing frameworks I know will lose all progress if one of the more sinister scenarios from the above list hard-crashed one or more of its processes. I needed a more robust solution.
Basically, the only hope of survival at this point is the kernel. Only the kernel has enough power to rein in rogue processes, and deal with hard crashes. So in my purpose-built multi-processing framework, every task runs in its own process, with inputs and outputs written to unique files. And crucially, if any task does not finish within a set amount of time, it and all of its children are killed.
It took me quite a while to figure out how to do this, so here's the deal:
# start your process with a new process group:
process = Popen(..., start_new_session=True)
# after a timeout, kill the whole process group:
process_group_id = os.getpgid(process.pid)
os.killpg(process_group_id, signal.SIGKILL)
This is the nuclear option. I tried SIGTERM and SIGHUP instead, but programs would happily ignore it. I tried killing or terminating only the process, but that would leave zombie children. Sending SIGKILL to the process group does not take prisoners. The processes do not get a chance to respond or clean up after themselves. But you know what, after months of dealing with this stuff, this is the first time that my experiments actually run reliably for a few days without crashing or exhausting some resource. If that's what it takes, so be it.
Qt for Python Video Tutorial
This video series was produced in the spring of 2020, during the COVID19-pandemic, when all lectures had to be held electronically, without physical attendance. It is a tutorial, in German, for building a small Qt GUI that visualizes the ongoing pandemic on a world map.
If the videos are too slow, feel free to speed them up by right-clicking, and adjusting play speed (Firefox only, as far as I know).
You may also download the videos and share them with your friends. Please do not upload them to social media or YouTube, but link to this website instead. If you want to modify them or create derivative works, please contact me.

The Qt for Python Video Tutorial by Bastian Bechtold is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Update: As of April 2022, all code examples have been updated to use PySide6. In particular, this changes the imports, replaces app.exec_() with app.exec(), and replaces mouseEvent.pos() with mouseEvent.position().toPoint() (see note in map11.py:).
1 Intro
Prerequisites: A basic understanding of Python, and a working installation of python ≥3.4.
An overview over the topics discussed in the rest of the videos, and installation of Qt for Python and Pandas.
2 Hello World
Our first GUI program, a window with a text label.
Code: map2.py
3 Main Window
Create a QMainWindow, and build some structure for later episodes.
Code: map3.py
4 Layouts
Position a QLabel and a QPushButton side by side, using layouts.
Code: map4.py
5 Signals and Slots
Make the button change the label's text if clicked.
Code: map5.py
6 Loading Data
Load the data required to draw a map.
Code: map6.py
Data: countries_110m.json
7 Drawing the Map
Draw a world map into a QGraphicsScene.
Code: map7.py
8 Pens and Brushes
Make the map pretty, using QPens and QBrushes.
Code: map8.py
9 Resize Event
Resize the map when the window size changes, by overloading resizeEvent.
Code: map9.py
10 Mouse Tracking
Highlight the country under the mouse.
Code: map10.py
11 Custom Signal
Respond to clicks of a country.
Code: map11.py
12 Addendum
Improve the code by cutting out a middle man.
Code: map12.py
13 Pandas
A quick introduction to Pandas.
Data: covid19.csv
14 Pandas Integration
Load the COVID19 dataset and print some stats.
Code: map14.py
15 Model View Tables
Display the COVID19 dataset in a QTableView.
Code: map15.py
16 Table Header Data
Fill in the table headers from the dataset.
Code: map16.py
17 Country Selection
Show only a subset of the dataset when a country is clicked.
Code: map17.py
18 Cleanup
Summary, and a few finishing touches.
Code: map18.py
The Value Proposition of Open Source Software
To quote Wikipedia:
Open Source Open-source software (OSS) is a type of computer software in which source code is released under a license in which the copyright holder grants users the rights to study, change, and distribute the software to anyone and for any purpose.
In practice, this generally means software developed by hobbyists in their free time, as opposed to professionals at a company.
But why should such software be preferable to commercial products? I shall ignore price, for the moment. While open source software generally does not cost money, I have no qualms about paying money for software, and can easily afford to, as well. So if it's not price, what then?
Richard Stallman makes an argument that it's all about Freedom. But I have a suspicion that he really wants the code to be free, not its users1. He argues that "free" licenses make the program's source code available to users. Presumably, to read it and change it. However, I don't do that, generally. And neither do I redistribute software, which is another "freedom" granted by Stallman-style free software. Also, you don't need access to the source code to change a software. But I still prefer Open Source Software to commercial software, in most cases.
And the reason is, that in my experience, Open Source Software is generally better software. And I believe the reason for this is incentives:
Open Source Software is generally created to scratch an itch. One single developer was sufficiently disgruntled to throw all caution into the wind, and solve the problem him/herself. Which means that at least one person was dissatisfied with the commercial offerings at the time.
And there are plenty of reasons to be dissatisfied with commercial software. Commercial software needs to make money. And to justify recurring sales, it must keep adding features, often beyond the usefulness to users. Thus, big changes and new features are incentivized, while continued refinement and bug fixing are merely cost centers.
Contrast this with Open Source Software, which is quite content to simply work. No new features need to be added if the software is complete as it is, and no new effort needs to be invested if there aren't any bugs remaining. Such software is a joy to use.
In the commercial world, such software is not stable, but stagnant. A sign of death, not maturity. And when commercial software dies, it is buried, never to be used again. And all the work its users have created with it over the years, becomes inaccessible and obsolete with it). In the same way, today's online-only subscription-based software distributions are essentially protection rackets that require a monthly ransom just to keep access to your existing work. The moment you stop paying, all your previous work becomes inaccessible. Such moves are indeed Stallman-worthy invasions of freedom that are unacceptable to me2.
Of course, Open Source Software allows users to contribute to the product. But In my own projects, I have found this to vary greatly between cultures. Some communities seem to be naturally tinker-friendly, such as Emacs or Darktable. Others, such as Python's or Matlab's, are strangely reluctant to help one another, with more users creating bug reports than contributors creating pull requests.
Funny enough, price does not enter this equation. Because what you need to use Open Source Software is often not money, but time. And only rich people have that. If you're poor, and paying for software is a problem, you're far more likely to pirate "professional" software with a known value proposition, than to spend time on an unknown quantity. Open Source Software is a toy for the rich, and paradoxically unattractive to people in need3.
So in summary, I have generally found Open Source Software to be better than commercial software in most circumstances. Perhaps as a next step, we should try to figure out how to get payed for creating it, and how to keep monetary incentives from ruining products.
See this link for an exhaustive discussion of that topic. It's an amazing article!↩
Except for video games, which I only consume once, and which result in experiences, not artifacts. Strange, how this distinction is surprisingly hard to justify.↩
User-facing software, that is. Linux web servers are for everyone↩
File Parsing with Python Video Tutorial
This video series was produced in the spring of 2020, during the COVID19-pandemic, when all lectures had to be held electronically, without physical attendance. It is a tutorial, in German, for parsing text files, and basic unit testing.
If the videos are too slow, feel free to speed them up by right-clicking, and adjusting play speed (Firefox only, as far as I know).
You may also download the videos and share them with your friends. Please do not upload them to social media or YouTube, but link to this website instead. If you want to modify them or create derivative works, please contact me.
The Qt for Python Video Tutorial by Bastian Bechtold is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
1 Intro
Prerequisites: A basic understanding of Python, and a working installation of python ≥3.6.
An overview over the topics discussed in the rest of the videos, and installation of pytest.
2 INI: First Steps
Basic setup, and our first test.
Code: inifile_1.py and inifile_test_1.py
3 INI: Sections
Parsing INI sections.
Code: inifile_2.py and inifile_test_2.py
4 INI: Variables
Parsing INI variable assignments.
Code: inifile_3.py and inifile_test_3.py
5 INI: Bugfixes and Integration Tests
Parsing difficult values, and comments.
Code: inifile_4.py and inifile_test_4.py
6 INI: Test the Tests
Tests can be wrong, too.
7 CSV: First Prototype
A simple parser for values without quotes.
Code: csvfile_1.py and csvfile_test_1.py
8 CSV: Quotes
Parsing quoted values makes everything harder.
Code: csvfile_2.py and csvfile_test_2.py
9 CSV: A Few More Features
Comments and a choice of separators.
Code: csvfile_3.py and csvfile_test_3.py
10 JSON: Keyword Parser
Parsing the simplest of JSON expressions.
Code: jsonfile_1.py and jsonfile_test_1.py
11 JSON: Strings
Parsing JSON strings is not as simple as it seems.
Code: jsonfile_2.py and jsonfile_test_2.py
12 JSON: Numbers
Numbers in JSON.
Code: jsonfile_3.py and jsonfile_test_3.py
13 JSON: Data Structures
The rest of JSON: Objects and Arrays.
Code: jsonfile_4.py and jsonfile_test_4.py
14 Regular Expressions 1
How to parse parts of INI files with regular expressions.
Code: inifile_regex.py
15 Regular Expressions 2
How to parse parts of JSON files with regular expressions.
Code: jsonfile_regex.py
16 Wrapup
A summary of the topics discussed.
How I Record Screen Casts
This semester is weird. Instead of holding my "Applied Programming" lecture as I normally would, live-coding in front of the students and narrating my foibles, this time it all had to be done online, thanks to the ongoing pandemic. Which meant I had to record videos. I had no idea how to record videos. This is a writeup of what I did, in case I have to do more of it. You can see the results of my efforts in my Qt for Python video tutorials and my file parsing with Python video tutorials. Through some strange coincidences, wired.com wrote an article about my use of OBS.
Working on Linux, I used the Open Broadcaster Software, or OBS for short, as my recording program. OBS can do much more than record screencasts, but I only use it for two things: Recording a portion of my screen, and switching between different portions.
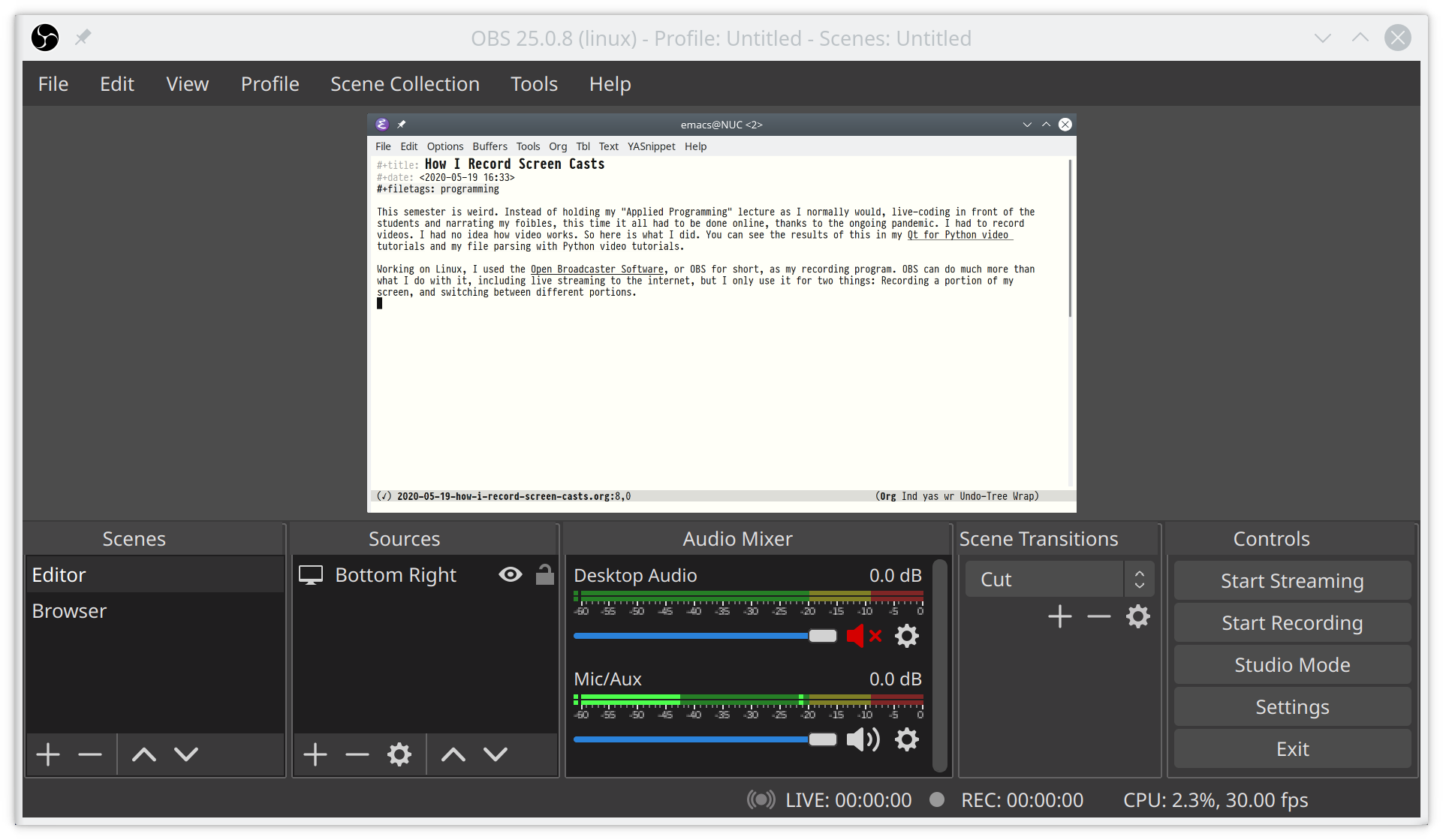
To this end, I divide my screen into four quadrants. The top left is OBS, for monitoring my recording and mic levels. The bottom left is a text editor with my speaker notes. The top right and bottom right are my two recording scenes, usually a terminal or browser in the top right, and a text editor in the bottom right. The screenshot shows the Editor scene, which has a filter applied to its source to record only the bottom right quadrant. On a 4K screen, each quadrant is exactly full HD.
In OBS's settings, I set hotkeys to switch scenes: I use F1 and F2 to select the Browser and Editor scenes, and F6 for starting and stopping recordings. For more compatible video files, I enable "Automatically remux to mp4" in OBS' advanced settings.
The second ingredient to my recording setup is KDE, where I assign F3 and F4 to activate the browser or editor window (right click any window → More Actions → Assign Window Shortcut). And to make my recordings look clean, I disable window shadows for the duration of the recording.
With these shortcuts, I hit F1 and F3 to switch focus and scene to the browser, or F2 and F4 for the text editor. To make this work smoothly, I disabled these shortcuts within my terminal, browser, and text editor. But always be weary of accidentally getting those out of sync. I don't know how often I accidentally recorded the wrong part of the screen and had to redo a recording.
Anyway, with this setup, I can record screen casts with very minimal effort. The last ingredient however is editing; and I loathe video editing. I'd much rather record a few more takes than spend the same time in a video editor. Instead, I record short snippets of a few minutes each, and simply concatenate them with FFmpeg:
Create a file concatenate.txt, that lists all the files to be concatenated:
file part-one.mp4
file part-two.mp4
file part-three.mp4
then run ffmpeg -f concat -i concatenate.txt -c copy output.mp4 to concatenate them into a new file output.mp4.
The great thing about this method is that it uses the copy codec, which does not re-encode the file. I.e. it only takes a fraction of a second, and does not degrade quality.
In summary, this setup works very well for me. It is simple and efficient, and does not require any video editing. The ability to switch scenes is cool and powerful. Still, recording videos is a lot of work. All in all, the 18 videos in the file parsing tutorials took 250 takes, according to my trash directory.
Two Years with Legacy Code
From January 2021 to the beginning of 2023, I worked on a legacy code base at Fraunhofer IDMT in Oldenburg. My task was the maintenance and development of a DNN-based speech recognition engine that had become terra incognita when its original developer had left the company a year before I started. The code had all the hallmarks of severe technical debt, with layers of half-used abstractions, many unused branches of unknown utility, and the handwriting of several concurrent programmers at odds with each other.
The code had evidently been written in a mad dash to bring the product to market. And not to discredit its developers, had been in production for several years, with a core of robust algorithms surrounded by helper scripts that had allowed the company to build upon, even after the original developers had left.
It was my job to clean it up. Having spent six years on my PhD recently, I welcomed the calmer waters of 'just' programming for a bit. This blog post is a summary of the sorts of challenges I faced during this time, and what kinds of techniques helped me overcome them.
The lay of the land
I approached the task from the outside, sorting through the build scripts first. Evidently, at least three authors were involved: One old-school Unix geek that wrote an outdated dialect of CMake, one high-level Python scripter, and one shell scripter that deeply believed in abstraction-by-information-hiding. The result of this was... interesting.
For a good few weeks I "disassembled" these scripts by tracing their execution manually through their many layers, and writing down the necessary steps that were actually executed. My favorite piece of code was a Makefile that called a shell script that ran a Python program, which instantiated a few classes and data structures, which ultimately executed "configure; make; make install" on another underying Makefile. I derived great satisfaction from cutting out all of these middle-men, and consolidating several directories of scripts into a single Makefile.
Similar simplifactions were implemented at the same time across several code bases by my colleagues. In due time, this concerted effort enabled us to implement continuous integration, automated benchmarking, and automated builds, but more on that later.
Data refactoring
The speech recognition software implemented a sort of interpreter for the DNN layers, originally encoded as a custom binary blob. Apparently, a custom binary approach had been taken to avoid dependencies on external parsing libraries. Yet the data had become so convoluted that both its compilation and its parsing were now considered unchangeable black boxes that impeded further development.
Again, I traced through the execution of the compiling code, noted down the pieces of data it recorded, and rewrote the compiler to produce a MsgPack file. On the parsing side, I wrote a custom MsgPack parser in C. Looking back, every job I've had involved writing at least a couple of data dumpers/parsers, yet many developers seem intimidated by such tasks. But why write such a thing yourself instead of using an off-the-shelf solution? In an unrelated code review later in the year one colleague used the cJSON library for parsing JSON; in the event, cJSON was several magnitudes bigger and more complex than the code base it was serving, which is clearly absurd. Our job as developers is to manage complexity, including that of our dependencies. In cases such as these, I often find a simple, fit-for-purpose solution preferable to more generalized external libraries.
A part of the DNN data came from the output of a training program. This output however was eternally unstable, often breaking unpredictably between version, and requiring complex workarounds to accommodate different versions of the program. The previous solution to this was a deeply nested decision tree for the various permutations the data could take. I simplified this code tremendously by calling directly into the other program's libraries, instead of trying to make sense of its output. This is another technique I had to rely on several times, hooking into C/C++ libraries from various Python scripts to bridge between data in a polyglot environment.
Doing these deep dives into data structures often revealed unintended entanglements. In order to assemble one data structure, you had to grab pieces of multiple different source data. Interestingly, once data structures were cleaned up to no longer have such entanglements, algorithms seemed to fall into place effortlessly. However, this was not a one-step process, but instead an ongoing struggle to keep data structures minimal and orthogonal. While algorithms and functions often feel easier to refactor than data structures, I have learned from this that it is often the changes to data structures that have the greatest effect, and should therefore receive the greatest scrutiny.
Code refactoring
My predecessor had left me a few screen casts by way of documentation. While the core program was reasonably well-structured, it was embedded in an architectural curiosity that told the tale of a frustrated high-level programmer forced to do low-level gruntwork. There were poor-man's-classes implemented as C structs with function pointers, there were do-while-with-goto-loops for exception handling, there were sort-of-dynamically-typed data containers, accompanied by angry comments decrying the stupidity of C.
Now I like my high-level-programming as much as the next guy, but forcing C to be something it isn't, is not my idea of fun. So over a few months I slowly removed most of these abstractions. Somewhat to my surprise, most of them turned out pure overhead that could simply be removed. Where a replacement was needed, I reverted to native C constructs. Tagged unions instead of casting, variable-length-arrays instead of dynamic arrays. Treating structs as values instead of references. This, alone, reduced the entire code base by a good 10%. The harder part was sorting out the jumble of headers and dependencies that had evidentally built up over time. Together with the removal of dead code paths, the overall code base shrank by almost half. There are few things more satisfying than excising and deleting unnecessary code.
I stumbled upon one particularly interesting problem when trying to integrate another code base into ours. Within our own software, build times were small enough to make logging and printf-debugging easier than an interactive debugger such as GDB. The other code base however was too complex to recompile on a whim, and a different solution had to be found. Now I am a weird person who likes to touch the raw command line instead of an IDE. And in this case this turned out to be a huge blessing, as I found that GDB can not only be used interactively, but can also be scripted! So instead of putting logging into the other library, I wrote GDB scripts that augmented break points with a little call printf(...) or print/d X. These could get suprisingly complicated, where one breakpoint might enable or disable other breakpoints conditionally, and break point conditions could call functions on their own. It took some learning, but these debugging scripts were incredibly powerful, and a technique I will definitely refer to in the future.
When adding new features to the software, I often found it impossible to work the required data flow into the existing program code without snowballing complexity. I usually took these situations as code smells that called for a refactoring. Invariably, each cleaning up of program flow or data structures inched the program closer and closer to allow my feature addition. After a while, this became an established modus operandi: independently clean the code until feature additions become easy and obvious, then do the obvious thing. Thus every task I finished also left the surrounding code in a better state. In the end, about 80% of the code base had gotten this treatment, and I strongly believe that this has left the project in a much better state than it was before. To say nothing of the added documentation and tests, of course.
More velocity makes bigger craters
As I slowly shifted from cleanup work to new features, change management became a pressing issue. New features had to be evaluated, existing features had to be tested, and changes had to be documented and downstreamed. Fascinatingly, the continuous integration and evaluation tools we built for this purpose, soon unearthed a number of hidden problems in other parts of the product that we had not been aware of (including that the main task I had been hired to do was less worthwhile than thaught, LOL). That taught us all a valuable lesson about testing, and proving our assertions. That said, I never found bottom-level unit tests all that useful for our purposes; the truly useful tests invariably were higher-level integration tests.
Eventually, my feature additions led to downstream changes by several other developers. While I took great care to present a stable API, and documenting all changes and behavior appropriately, at the end of the day my changes still amounted to a sizeable chunk of work for others. This was a particularly stark contrast to the previous years of perfect stagnation while nobody had maintained the library. My main objective at this point was to avoid the mess I had started out with, where changes had evidentally piled on changes until the whole lot had become unmaintainable.
Thus a balance had to be struck between moving fast (and breaking things), and projecting stability and dependability. One crucial tool for this job turned out to be code reviews. By involving team members directly with the code in question, they could be made more aware of its constraints and edge cases. It took a few months to truly establish the practice, but by the end of a year everyone had clearly found great value in code reviews as a tool for communication.
Conclusions
There is a lot more to be said about my time at Fraunhofer. The deep dive into the world of DNN engines was truly fascinating, as were the varied challenges of implementing these things on diverse platforms such as high-performance CPU servers, Laptops, Raspberry Pis, and embedded DSPs. I learned to value automation of developer tasks, and of interface stability and documentation for developer productivity.
But most of all, I learned to appreciate legacy code. It would have been easy to call it a "mess", and advocate to rewrite it from scratch. But I found it much more interesting to try to understand the code's heritage, and tease out the algorithmic core from the abstractions and architectural supports. There were many gems to be found this way, and a lot to be learned from the programmers before you. I often felt a strange connection to my predecessor, as if we were talking to each other through this code base. And no doubt my successor feels the same way about my code now.
